1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
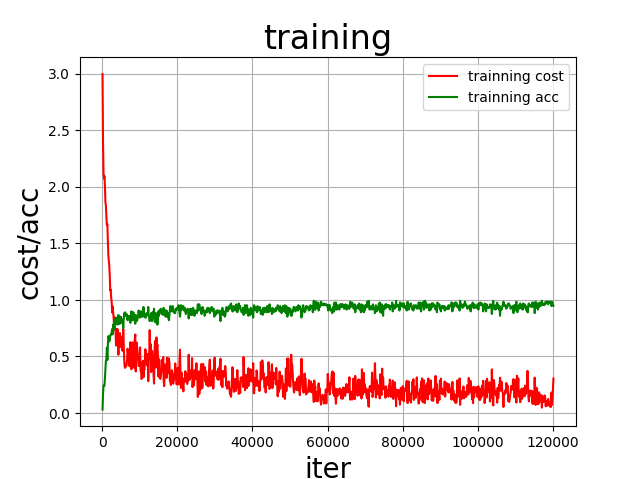
| def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
EPOCH_NUM = 2
model_save_dir = "CH4_File/model"
for pass_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
all_train_iter = all_train_iter + BATCH_SIZE
all_train_iters.append(all_train_iter)
all_train_costs.append(train_cost[0])
all_train_accs.append(train_acc[0])
if batch_id % 200 == 0:
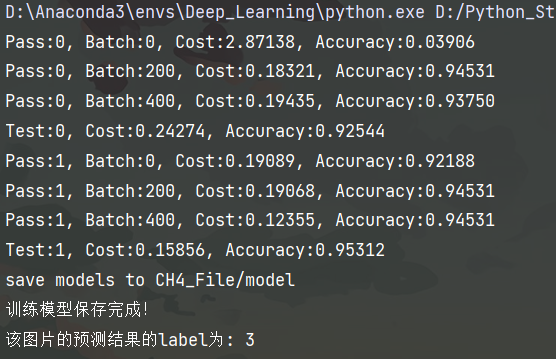
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
test_accs = []
test_costs = []
for batch_id, data in enumerate(test_reader()):
test_cost, test_acc = exe.run(program=test_program,
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
test_accs.append(test_acc[0])
test_costs.append(test_cost[0])
test_cost = (sum(test_costs) / len(test_costs))
test_acc = (sum(test_accs) / len(test_accs))
print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (pass_id, test_cost, test_acc))
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
print('save models to %s' % (model_save_dir))
fluid.io.save_inference_model(model_save_dir,
['image'],
[predict],
exe)
print('训练模型保存完成!')
draw_train_process("training", all_train_iters, all_train_costs, all_train_accs, "trainning cost", "trainning acc")
def load_image(file):
im = Image.open(file).convert('L')
im = im.resize((28, 28), Image.ANTIALIAS)
im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)
im = im / 255.0 * 2.0 - 1.0
return im
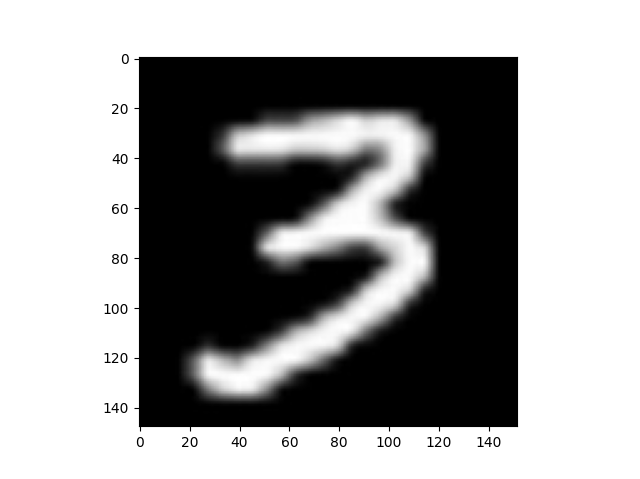
infer_path='CH4_File/data/infer_3.png'
img = Image.open(infer_path)
plt.imshow(img)
plt.show()
|
.jpg)
.jpg)