.jpg)
Paper Reading 5|Swin Transformer:Hierarchical Vision Transformer using Shifted Windows
引言
作者的目的:就网络结构而言,CNN在计算机视觉上处于统治地位,Transformer在NLP上处于统治地位,作者想扩展Transformer在计算机视觉上比肩CNN,使其能够作为计算机视觉各种任务通用的骨干。
两个挑战:
- 规模(scale):与word token在transformer中作为基本处理元素不同,视觉元素可以在规模上有很大的变化,这是一个在对象检测等任务中需要注意的问题。在现有的基于transformer的视觉模型中,token都是固定规模的,这一属性不适合这些视觉应用。
- 分辨率(resolution):图像的像素分辨率比文字段落中的文字高得多,目前存在许多视觉任务,如语义分割,需要在像素级进行密集预测,而这在高分辨率图像上对于Transformer来说是难以实现的,因为其自注意的计算复杂度是图像大小的二次方。
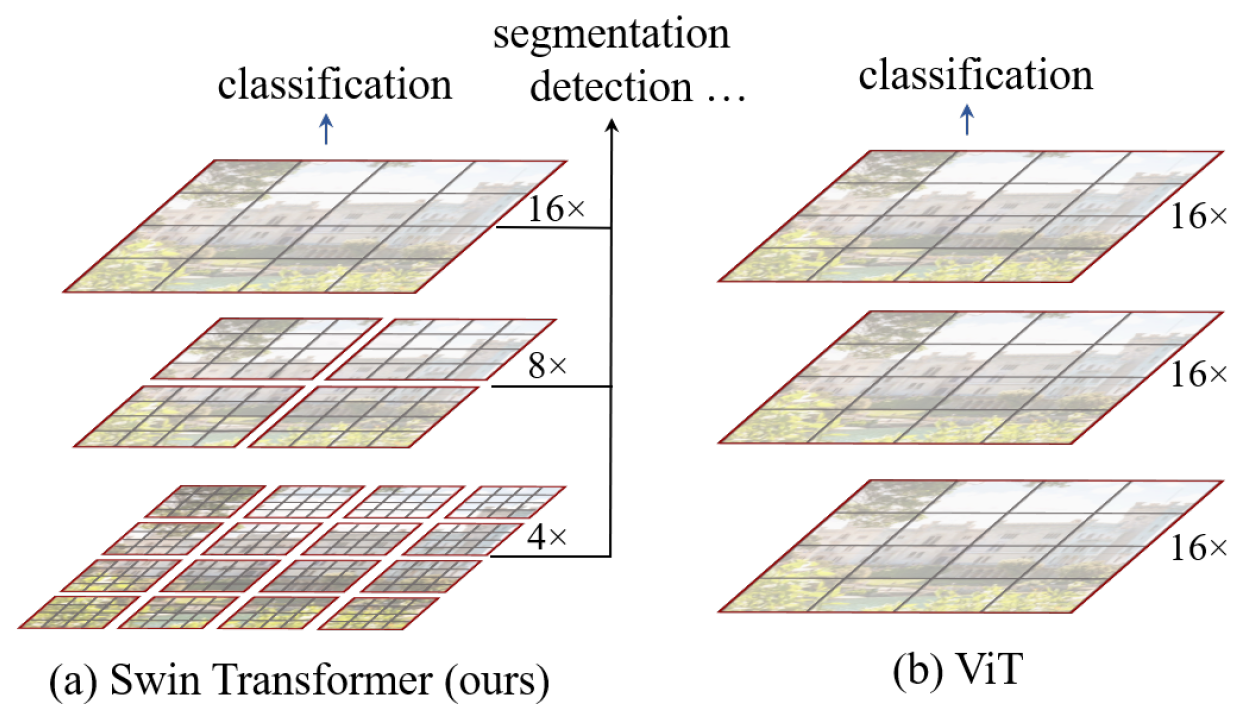
为了克服这些问题,作者提出了一个通用的Transformer主干,称为Swin-Transformer,它构建分层特征映射,计算复杂度与图像大小成线性关系,如图1(a)所示,Swin Transformer构建了一个分层表示,从较小的补丁(用灰色表示)开始,逐渐将相邻的补丁合并到更深的Transformer层中。通过这些分层特征映射,Swin Transformer模型可以方便地利用高级技术进行密集预测,如**特征金字塔网络(FPN)[42]或U-Net[51]**。线性计算复杂度是通过在划分图像(用红色表示)的非重叠窗口中局部计算自我注意来实现的。由于每个窗口中的patch数量是固定的,因此复杂度与图像大小成线性关系。这些优点使Swin Transformer适合作为各种视觉任务的通用骨干,而不像以前的基于Transformer的架构[20],后者生成单一分辨率的特征图,复杂度为二次型。
.jpg)
评论