.jpg)
Paper Translation 3|Multiple Wavelet Pooling for CNNs
Multiple Wavelet Pooling for CNNs
Abstract
池化层是任何卷积神经网络的重要组成部分。最流行的池化方法,如最大池化或平均池化,都是基于邻域方法,可能过于简单,容易造成视觉失真。为了解决这些问题,最近提出了一种基于Haar小波变换的池化方法。遵循同样的研究思路,在这项工作中,我们探索使用更复杂的小波变换(Coiflet, Daubechies)来执行池化。此外,考虑到小波与滤波器的工作原理类似,我们提出了一种结合多个小波变换的卷积神经网络池化方法。实验结果证明了我们的方法的优点,提高了在不同公共目标识别数据集上的性能。
1 介绍
神经网络作为深度学习的主要工具,在计算机科学史上可谓前前后后。池化层是卷积神经网络(cnn)的主要组成部分之一。它们旨在压缩信息,即减少数据维度和参数,从而提高计算效率。由于cnn处理的是整个图像,神经元的数量会增加,计算成本也会增加。因此,需要对数据和参数的大小进行某种控制。然而,这并不是使用池化方法的唯一原因,因为它们对于执行多级分析也非常重要。这意味着,我们查找的不是激活发生的确切像素,而是它所在的区域。池化方法从确定性的简单方法(如最大池化)到概率性的更复杂的方法(如随机池化)各不相同。所有这些方法的共同点是,它们使用邻域方法,尽管速度很快,但会引入边缘晕、模糊和混叠。具体来说,max pooling是一种通常有效的基本技术,但是可能太简单了,因为它忽略了只在激活映射上应用max操作的大量信息。另一方面,平均池化更能抵抗过拟合,但它会对某些数据集产生模糊效果。选择正确的池化方法是获得良好效果的关键。
近年来,小波因不同的目的被纳入到深度学习框架中[4,3,8],其中包括池化函数[8]。在[8]中,作者提出了一个池化函数,该函数根据快速小波变换(FWT)在小波域中进行二阶分解。作者证明了他们提出的方法优于或优于传统的池化方法。
在本文中,受[8]的启发,我们探索了不同小波变换作为池化方法的应用,并在它们的最佳组合的基础上提出了一种新的池化方法。我们的工作与[8]的区别主要体现在三个方面:
- 我们根据离散小波变换(DWT)在小波域进行一阶分解,因此,我们可以直接从low-low (LL)子带中提取图像
- 我们探索不同的小波变换,而不是只使用Haar小波
- 我们提出了一种基于不同小波变换组合的池化方法。
文章的结构如下。在第2节中,我们介绍了多小波池化方法,在第3节中,我们介绍了数据集,实验设置,讨论结果和描述结论。
2 多小波池化
小波变换是数据的一种表示,类似于傅里叶变换,它允许我们压缩信息。给定光滑函数f(t),连续情况定义为:
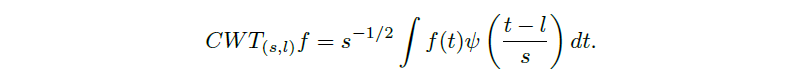
其中ψ(t)为母小波,s∈Z为尺度指标,l∈Z为位置指标。给定一个大小为(n, n, m)的图像A,可以通过构建矩阵来实现有限离散小波变换(DWT),在[2]中解释如下:
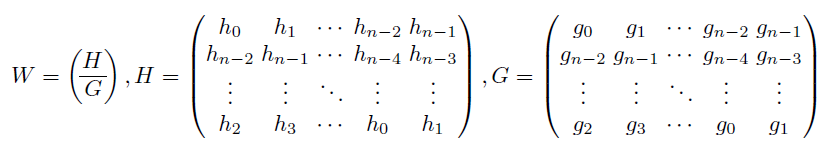
将原始图像A变换为4个子带:LL子带是由低频分量组成的低分辨率残差,这意味着它是我们原始图像的近似;子带HL、LH和HH分别给出了水平、垂直和对角线的细节。
在本文中,我们提出通过组合不同的小波:Haar, Daubechie和Coiflet[1]小波来形成池化层。
多小波池化算法如下:
选择两个不同的小波基,计算它们的相关矩阵W1和W2。
提出图像特征F,并行进行两个相关的离散小波变换W1FW1T和W2FW2T。
从每个矩阵中丢弃HL, LH, HH,从而只考虑两种不同基逼近的图像LL1和LL2。
连接两个结果并传递到下一层。
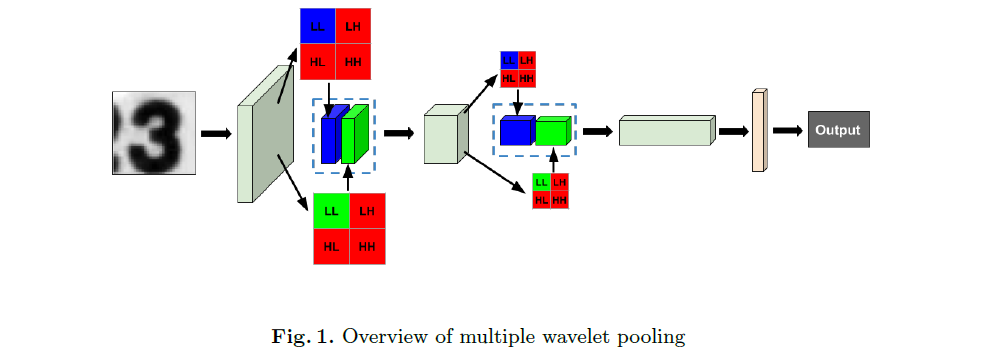
在图1中,我们可以看到这个池化方法在CNN架构中是如何工作的。
3 实验结果与结论
我们使用了三个不同的数据集进行测试:MNIST[6]、CIFAR-10[5]和SVHN[7]。为了比较收敛性,我们使用了分类熵损失函数;作为度量标准,我们使用精度。对于MNIST数据集,我们使用了600批大小,我们执行了20个epoch,我们使用了0.01的学习率。对于CIFAR-10数据集,我们执行了两个不同的实验:一个没有dropout,有45个epoch,另一个有dropout,有75个epoch。对于这两种情况,我们都使用动态学习率。对于SVHN数据集,我们进行了一组具有45个epoch和动态学习率的实验。所有的CNN结构都是从各自数据集的[8]获取的。在这种情况下,我们测试没有dropout的算法,以观察池化方法对过拟合的阻力。只有在CIFAR-10的情况下,我们考虑了有退出和没有退出的性能。
表1显示了每种池化方法的准确度及其在排名中的位置;此外,我们用粗体突出显示每个数据集的最佳性能。当我们用dropout进行模型训练时,我们将用“d”表示情况。对于MNIST数据集,与Haar基相比,选择Daubechie基提高了准确性。对于CIFAR-10和SVHN,我们可以看到多小波池化的性能是均匀的,甚至优于max和average池化。特别是对于dropout的情况,多小波池化算法优于其他所有池化算法。