.jpg)
Paper Translation 4|Object detection method for ship safety plans using deep learning
Object detection method for ship safety plans using deep learning
0 Abstract
During the safety inspection of a ship, there is a stage confirming whether the safety plan is designed in accordance with the regulations. In this process, an inspector checks whether the location and number of various objects (safety equipment, signs, etc.) included in the safety plan meet the regulations. Manually converting the information of objects existing in the ship safety plan into digital data requires significant effort and time. To overcome this problem, a technique is required for automatically extracting the location and information of the object in the plan. However, owing to the characteristics of the ship safety plan, there are frequent cases in which the detection target overlaps with noise (figure, text, etc.), which lowers the detection accuracy. In this study, an object detection method that can effectively extract the object quantity and location within the ship safety plan was proposed. Among various deep learning models, suitable models for object detection in ship safety plans were compared and analyzed. In addition, an algorithm to generate the data necessary for training the object detection model was proposed and adopted the feature parameters, which showed the best performance. Subsequently, a specialized object detection method to rapidly process a large ship safety plan was proposed. The method proposed in this study was applied to 15 ship safety plans. Consequently, an average recall of 0.85 was achieved, confirming the effectiveness of the proposed method.
船舶安全检查过程中,有一个确认安全方案是否按规定设计的阶段。在此过程中,检查员检查安全计划中所包含的各种物体(安全设备、标志等)的位置和数量是否符合规定。将船舶安全计划中存在的物体信息手动转换为数字数据需要大量的精力和时间。为了解决这一问题,需要一种自动提取规划目标位置和信息的技术。但由于舰船安全方案的特点,检测目标与噪声(图像、文字等)重叠的情况时有发生,降低了检测精度。本文提出了一种能够有效提取船舶安全计划中目标数量和位置的目标检测方法。在各种深度学习模型中,对适合舰船安全计划目标检测的模型进行了比较和分析。此外,提出了一种生成训练目标检测模型所需数据的算法,该算法采用的特征参数表现出最佳性能。。随后,提出了一种用于快速处理大型船舶安全方案的目标检测方法。本研究提出的方法已应用于15个船舶安全计划。平均召回率为0.85,验证了该方法的有效性。
1 Introduction
1.1 Research background
To examine whether safety regulations of ships are met, the register of shipping should check the installation location and quantity of various safety and lifesaving devices. A plan containing this information is called a ship safety plan (thereafter referred to as a safety plan). Shipbuilding companies produce safety plans according to the regulations of the International Maritime Organization (IMO) (2003; 2017). For example, they should represent the installed devices in the same format as defined in Table 1. Subsequently, the ship owner or ship-building company provides a safety plan to the register of shipping for inspection. This plan is usually delivered in a non-editable document in various formats such as Portable Document Format (PDF), Joint Photograph Experts Group (JPEG), or Portable Network Graphics (PNG), because of confidentiality issues. Aforementioned formats are unable to provide detailed information (location, quantity, type, etc.) of the inserted devices. Therefore, the inspector needs to inspect procedures manually because of insufficient information.
船舶登记机关为检查船舶是否符合安全规定,应检查各种安全救生装置的安装位置和数量。包含这些信息的计划称为船舶安全计划(以后称为安全计划)。造船企业根据国际海事组织(IMO)(2003年;2017)。例如,它们应该以表1中定义的相同格式表示已安装的设备。随后,船东或造船公司向船舶注册机构提供一份安全计划,以供检查。由于保密问题,该计划通常以各种格式(如便携式文件格式(PDF)、联合摄影专家组(JPEG)或便携式网络图形(PNG))等不可编辑的文件形式交付。上述格式无法提供插入设备的详细信息(位置、数量、类型等)。因此,由于资料不足,检验员需要手工检查程序。
Owing to the characteristics of the shipbuilding industry, safety plans are extensive and complex, requiring an inordinately large amount of labor for relatively simple work. In particular, a device (hereafter referred to as an object) in a safety plan is small, less than 0.003% of the total safety plan size on average, and the number of objects is mostly 800 or above. Consequently, several inspectors must manually inspect the location and quantity of each object over several days. In addition, there might be a difference in the results according to the proficiency levels of the inspectors. Therefore, various additional tasks may be necessary, such as collecting the results of each inspector for the final revision.
由于造船业的特点,安全计划广泛而复杂,相对简单的工作需要大量的劳动力。具体而言,安全计划中的设备(以下简称对象)较小,平均小于总安全计划尺寸的0.003%,对象数量多为800个及以上。因此,若干视察员必须在几天内人工检查每个物体的位置和数量。此外,根据检查员的熟练程度,结果也可能有所不同。因此,各种额外的任务可能是必要的,例如为最终的修订收集每个检查人员的结果。
In this study, an object detection model was applied to automate the aforementioned inspection procedure for a safety plan. Object detection refers to a task that requires an algorithm to localize all objects in the image (Russakovsky et al., 2015). The proposed model requires a safety plan as input and detects the objects; subsequently, the location and quantity of objects are organized. As a result, the time needed for the inspection procedure can be saved.
在本研究中,本研究应用目标检测模型,实现上述安全计划检测过程的自动化。对象检测是指需要一种算法来定位图像中所有对象的任务(Russakovsky et al., 2015)。该模型以安全计划为输入,对目标进行检测;随后,组织对象的位置和数量。因此,可以节省检验程序所需的时间。
1.2 Related works
Research on detecting target objects within input images has been actively conducted in various fields. The algorithms for detecting objects can be divided into two types, as follows:
- Decomposing objects into primary elements (such as lines, arcs, and circles) and finding them in input images
- Matching objects to a region of input images directly
对输入图像中目标物体的检测在各个领域都有积极的研究。检测对象的算法可以分为两类:
将对象分解为主要元素(如线、弧和圆),并在输入图像中找到它们
将对象直接匹配到输入图像的区域
To execute the former algorithm, the structural characteristics of the target object should be determined. The target object is decomposed into primary elements, and geometric relationships between them are determined. If a region of the primary elements has a similar part of the geometric relationships of the target object, the region can be considered as the target object; this method is known as a case-based algorithm. Luo and Liu (2003) proposed ten geometric relationships to define a target object consisting of a circle and two horizontal straight lines. This al-gorithm can achieve approximately 100% detection accuracy when the target object and input image are simple. However, as the shape of the target object becomes more complex, the number of geometric re-lationships increases exponentially. Moreover, the detection accuracy rapidly decreases in overlapping objects. Another limitation is that the detection accuracy is significantly affected by the quality and angle of the target object and input image.
要执行前一种算法,需要确定目标对象的结构特征。将目标对象分解为基本元素,确定它们之间的几何关系。如果一个区域的初级元素与目标对象有相似的部分几何关系,可以认为该区域是目标对象;这种方法被称为基于案例的算法。Luo和Liu(2003)提出了十种几何关系来定义一个由圆和两条水平直线组成的目标对象。在目标对象和输入图像比较简单的情况下,该算法可以达到约100%的检测精度。然而,随着目标对象的形状变得更加复杂,几何关系的数量呈指数增长。此外,在目标重叠的情况下,检测精度会迅速下降。另一个局限性是检测精度受目标物体和输入图像的质量和角度影响较大。
However, in the latter case, the algorithm directly compares whether there is a region similar to the target object in the input image. Subsequently, it detects the region with the highest correlation as the target object. Before the advent of deep learning technology, the sliding- window algorithm was primarily used to detect objects in images (Gualdi et al., 2012). The sliding-window algorithm detects the highest correlation position as the target object by moving around the detection window, as shown in Fig. 1. However, this method has the disadvantage of lowering the detection accuracy when the quality of the object to be searched in the image is not good or when rotation, deformation, and overlapping occur. Therefore, it is essential to rearrange images or remove unnecessary elements through image preprocessing before detection to prevent these problems. The method of moving around the detection window and performing a specific calculation within the window is known as the sliding-window algorithm.
而对于后一种情况,算法直接比较输入图像中是否存在与目标对象相似的区域。然后检测相关度最高的区域作为目标对象。在深度学习技术出现之前,滑动窗算法主要用于检测图像中的目标(Gualdi et al., 2012)。滑动窗口算法通过在检测窗口周围移动,将相关度最高的位置检测为目标对象,如图1所示。但是,当图像中待搜索对象的质量不佳或发生旋转、变形和重叠时,该方法的缺点是会降低检测精度。因此,在检测前必须对图像进行重新排列或者通过图像预处理去除不必要的元素,以防止这些问题的发生。在检测窗口周围移动并在窗口内执行特定计算的方法被称为滑动窗口算法。

In the 2000s, deep learning technology developed significantly, and emerged as an alternative solution to overcome excessive reliance on the quality of the input image. Generally, the deep learning method is defined as a set of machine learning algorithms that train a model through a large amount of data and attempt high-level abstraction using the trained model (Bengio et al., 2013). Specifically, it extracts critical features from a large amount of data or complex data through the training process. Therefore, a deep learning method can build a model that summarizes the characteristics of a target object, and can detect the target object by locating features in an input image.
进入21世纪后,深度学习技术得到了显著的发展,并成为克服对输入图像质量过度依赖的替代解决方案。通常,深度学习方法被定义为一组机器学习算法,通过大量数据训练模型,并尝试使用训练后的模型进行高层抽象(Bengio et al., 2013)。具体来说,它通过训练过程从大量数据或复杂数据中提取关键特征。因此,深度学习方法可以建立一个总结目标对象特征的模型,并通过在输入图像中定位特征来检测目标对象。
In the field of object detection in a plan, most of the relevant research focuses on piping and instrumentation diagram (P&ID). Yu et al. (2019) applied the modified sliding-window algorithm with AlexNet (Krizhev-sky et al., 2017), which is a deep learning model used for classification. Through this model, an accuracy of over 90% was achieved for four types of objects considering rotation. The sliding-window algorithm requires high computation time because it searches the entire image. Therefore, beyond the classification of an input image, object detection that directly specifies the location of an object and categorizes a class has recently become popular. Rahul et al. (2019) used fully convolutional networks (FCN) (Shelhamer et al., 2017) to recognize 11 types of objects in P&ID and showed high accuracy with an average F1-score of 0.94. Similarly, Yun et al. (2020) assigned ten types of objects in P&IDs as the target to be detected. They used the regions with CNN features (R–CNN) model (Girshick et al., 2014) modified for the environment of P&ID and achieved an average F1-score of 0.92.
在目标检测领域,大多数相关的研究都集中在管道和仪表图(P&ID)上。Yu等人(2019)将改进的滑动窗口算法与AlexNet (Krizhev-sky等人,2017)结合使用,AlexNet是用于分类的深度学习模型。通过该模型,对四种考虑旋转的物体,精度均达到90%以上。滑动窗口算法需要对整个图像进行搜索,计算时间较长。因此,除了对输入图像进行分类之外,直接指定对象位置并对类进行分类的对象检测最近变得很流行。Rahul等人(2019)使用完全卷积网络(FCN) (Shelhamer等人,2017)在P&ID中识别了11种类型的对象,并显示出较高的准确性,f1平均得分为0.94。同样,Yun et al.(2020)在p&id中指定了10种类型的物体作为待检测的目标。他们使用了带有CNN特征的区域(R-CNN)模型(Girshick et al., 2014),该模型针对P&ID的环境进行了改进,f1平均得分为0.92。
In the field of naval architecture and ocean engineering, several machine learning models have been proposed. Lee et al. (2020) detected ships in images using the Faster R–CNN model and tracked them using a Kalman filter. Kim et al. (2020) trained the existing ocean weather data using the convolutional long short-term memory (LSTM) model (Shi et al., 2015), which is effective in processing time-series data, and used the model for ocean weather prediction. Furthermore, using these advantages, Lee et al. (2021) estimated the required horsepower for the ship’s operation using the LSTM model and predicted the fuel oil consumption. Choi et al. (2020) proposed a model that predicts the wave height from an image of the sea using convolutional LSTM. In addition to deep learning models, in the field of machine learning, there is a model called reinforcement learning that takes actions and learns the consequences to make decisions autonomously in specific situations. Zhao and Roh (2019) proposed a collision avoidance method that considers equations of the motion of a ship by applying a deep reinforcement learning (DRL) model (Mnih et al., 2013). By expanding this, Chun et al. (2021) proposed a DRL-based collision avoidance model for autonomous ships to decide their avoidance routes and navigate autonomously. However, research on the detection of plans in naval architecture and ocean engineering is rare.
在造船和海洋工程领域,已经提出了几种机器学习模型。Lee等人(2020)使用Faster R-CNN模型检测图像中的船只,并使用卡尔曼滤波器跟踪它们。Kim等人(2020)利用卷积长短时记忆(LSTM)模型(Shi et al., 2015)对已有的海洋天气数据进行训练,该模型对时间序列数据处理有效,并用于海洋天气预报。此外,利用这些优势,Lee等人(2021年)利用LSTM模型估计了船舶运行所需的马力,并预测了燃油消耗。Choi等人(2020)提出了一种利用卷积LSTM从海洋图像预测海浪高度的模型。除了深度学习模型,在机器学习领域,还有一种叫做强化学习的模型,它采取行动并学习结果,在特定的情况下自主做出决定。Zhao和Roh(2019)提出了一种通过应用深度强化学习(DRL)模型来考虑船舶运动方程的避碰方法(Mnih et al., 2013)。在此基础上,Chun等人(2021)提出了一种基于drl的船舶避碰模型,用于自主船舶决定避碰路线和自主航行。然而,在船舶工程和海洋工程中,对平面图检测的研究还很少。
In this study, the input image was the safety plan, in which the target objects frequently overlapped with other objects, lines, or texts. Furthermore, if these objects are classified in the same class, there might be a difference in the expression method depending on the safety plan designer. In addition, because the target objects are significantly small compared with the size of the safety plan, a specialized object detection algorithm is required. Therefore, this study proposes an object detection method that effectively founds objects in an enormous safety plan. Furthermore, a data generation model is proposed that makes training data automatically without a time-consuming labeling process.
在本研究中,输入图像为安全计划,目标对象经常与其他对象、线条或文本重叠。此外,如果这些对象属于同一类,则表达式方法可能会有差异,这取决于安全计划设计器。此外,由于目标对象相对于安全计划的规模而言明显较小,因此需要专门的目标检测算法。因此,本研究提出了一种在庞大的安全计划中有效发现目标的目标检测方法。此外,提出了一种数据生成模型,使训练数据自动生成,而无需费时的标记过程。
2 Theoretical background
2.1 Overall process of the object detection in the safety plan(安全方案中物体检测的整体过程)
The overall process for detecting an object in the safety plan of this study is illustrated in Fig. 2. This study mainly comprises an object detection model, a training data generation model, and an object detection application.
First, to detect objects in the safety plan, the Faster RCNN model was used as the object detection model. The sliding-window and non-maximum suppression (NMS) algorithms were used together as detection algorithms (Fig. 2-(a)). Because a large amount of training data was required to train the object detection model, a specific training data generation model was proposed, as shown in Fig. 2-(b), to cover the insufficient data. Finally, the object detection model was applied to detect objects in the safety plan, as shown in Fig. 2-(c).
Detailed procedures for each part are described in forthcoming sections.
本研究安全方案中物体检测的总体流程如图2所示。本研究主要包括目标检测模型、训练数据生成模型和目标检测应用。
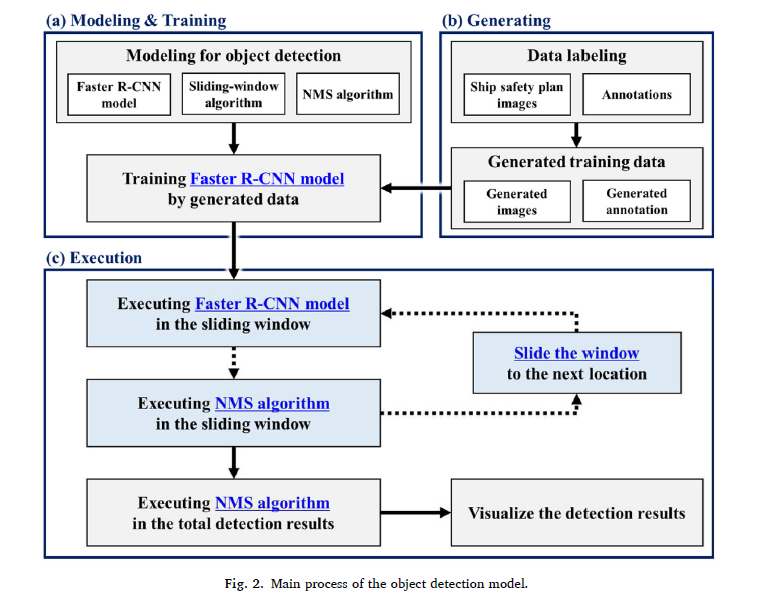
首先,对安全计划中的对象进行检测,使用Faster RCNN模型作为对象检测模型。检测算法采用滑动窗口算法和非最大抑制算法(NMS)相结合(图2-(a))。由于训练目标检测模型需要大量的训练数据,为了弥补不足的数据,我们提出了如图2-(b)所示的训练数据生成模型。最后,利用对象检测模型对安全方案中的对象进行检测,如图2-(c)所示。
每个部分的详细过程将在后面的小节中描述。
2.2 Detection target of the safety plan (安全计划的检测目标)
The input safety plan can be divided into two major parts, as shown in Fig. 3. The safety plan was divided into a region showing firefighting and safety devices with specific symbols and a table summarizing the information of objects. In addition, the characteristics of an object were represented by a text of connotations around the object. The object table contained information on the expression method, name, and quantity of each object. In this study, the objects were classified by IMO classifications (2003; 2017), which are referred to as classes.
输入安全方案可分为两大部分,如图3所示。安全计划被划分为一个区域,显示消防和安全设备,并有特定的符号和一个表格,总结物体的信息。此外,一个对象的特征是由一个文本的内涵围绕对象。对象表包含关于每个对象的表达式方法、名称和数量的信息。本研究采用IMO (2003;2017年),被称为类。
Every object in the safety plan must meet the requirement of a specific location and quantity according to shipping regulations; therefore, the register of shipping must inspect this aspect to ensure safety. This study can support the inspection procedure by automatically detecting the location and quantity of objects in a safety plan.
安全计划中的每一件物品都必须符合航运规定的特定地点和数量的要求;因此,船级社必须在这方面进行检查,以确保安全。该研究可通过自动检测安全计划中物体的位置和数量来支持检测过程。
Object detection models mostly require image formats such as JPEG and PNG for input values. However, most designers provide a safety plan in a PDF document in which size information, such as pixels, is not provided. Therefore, to match the input format, a PDF document must be converted into JPEG format.
对象检测模型大多需要JPEG和PNG等图像格式作为输入值。然而,大多数设计师在PDF文档中提供了一个安全方案,其中没有提供像素等大小信息。因此,为了匹配输入格式,必须将PDF文档转换为JPEG格式。
The converted image size depends on the output dots per inch (DPI). DPI refers to the number of pixels included in a length of 1 inch; hence, it is used as a measure of resolution. As the DPI increases, there is a possibility that the objects in the safety plan become more explicit, leading to an increase in detection accuracy. However, conversion to a specific DPI requires a significant amount of memory because of the enormous size of a safety plan. Therefore, it is necessary to set an appropriate DPI to prevent an out-of-memory problem.
转换后的图像大小取决于每英寸输出点(DPI)。DPI是指长度为1英寸内包含的像素个数;因此,它被用作分辨率的衡量标准。随着DPI的增加,安全计划中的对象有可能变得更加明确,从而导致检测精度的提高。但是,由于安全计划的巨大规模,转换到特定的DPI需要大量内存。因此,有必要设置适当的DPI以防止内存不足问题。
Next, a procedure for cropping the safety plan is required before inputting it into the object detection model. Excluding the target area, the safety plan consists of a table that indicates the location and quantity of objects, and title area. This part has the problem of false detection of an object, leading to an increased detection time. Therefore, specifying the detection area of the drawing can minimize the detection time when using an object detection model.
然后,在将安全计划输入到目标检测模型之前,需要对其进行裁剪。除目标区域外,安全计划由一个表组成,该表表示物体的位置和数量,以及标题区域。这部分存在误检物体的问题,导致检测时间增加。因此,在使用物体检测模型时,指定图纸的检测区域可以最大限度地减少检测时间。
2.3 Generation of training data for object detection (生成用于目标检测的训练数据)
In general, training a deep learning model requires enormous training data. However, the input safety plan is very large, and there are hundreds of objects that need to be detected in the safety plan. In addition, manually labeling more than 100 classes of objects to use as training data is time consuming and labor intensive. Therefore, a method for creating training data by randomly generating images using automated labeling was proposed in this study.
一般来说,训练一个深度学习模型需要大量的训练数据。但是,输入安全计划非常大,安全计划中需要检测的对象有数百个。此外,手动标记100多个类别的对象作为训练数据是耗时和劳动密集型的。因此,本研究提出一种利用自动标记随机生成图像来生成训练数据的方法。
There are various methods for generating virtual data. One of them is using generative adversarial networks (GAN) (Goodfellow et al., 2014), which has been studied a lot recently to generate virtual images. GAN is a method of generating virtual data close to real data using two models of generator and discriminator. It has the advantage of diversifying data because it directly creates a virtual image rather than a combination of existing images. However, it was not suitable in this study because it was difficult to specify the object’s location in the generated image.
生成虚拟数据的方法有很多种。其中一种就是生成对抗网络(GAN) (Goodfellow et al., 2014),它是近年来被大量研究的虚拟图像生成方法。GAN是一种利用生成器和鉴别器两种模型生成接近真实数据的虚拟数据的方法。它具有数据多样化的优点,因为它直接创建一个虚拟映像,而不是现有映像的组合。然而,由于在生成的图像中很难确定目标的位置,因此不适用于本研究。
Furthermore, GAN had to be learned through a large amount of training data. Radford et al. (2016) conducted a study to generate a human face with a small size of 64px × 64px through deep convolutional GAN (DCGAN). They obtained 3 M images from 10 K people and used 350,000 face boxes to train the GAN. However, since the training image size was 416px × 416px and the number of safety plan data we had was only 15, we could not guarantee good results for generating training data using GAN.
此外,GAN需要通过大量的训练数据来学习。Radford et al.(2016)研究了通过深度卷积GAN (DCGAN)生成大小为64px × 64px的人脸。他们从10 K个人那里获得了3 M张图像,并使用了35万个脸盒来训练GAN。但是由于训练图像的尺寸为416px × 416px,而我们拥有的安全计划数据数量只有15个,因此我们不能保证使用GAN生成训练数据的良好结果。
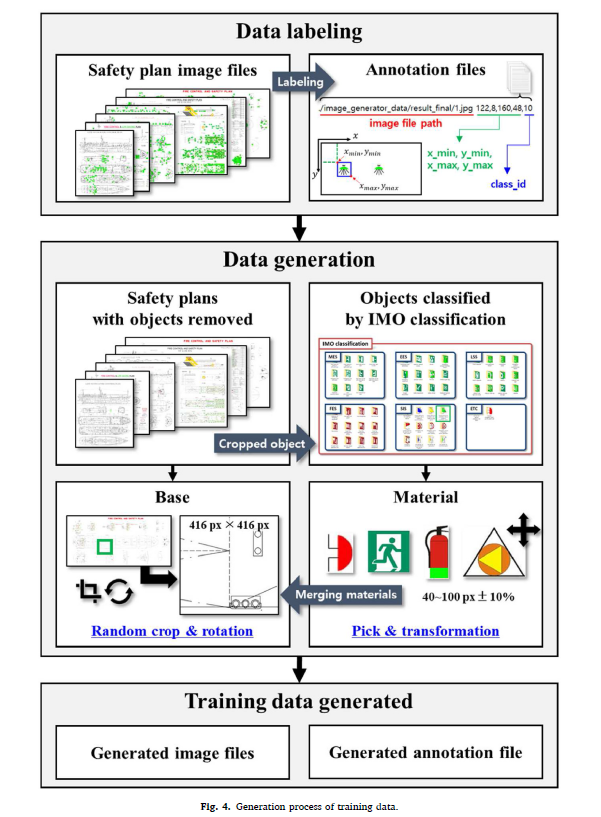
Therefore, this study used a simple method to place the object on the image randomly. This method is easy to devise and has the advantage that the labeling data can be obtained together because we know the object’s location. However, since there are limitations in the generation method, it is essential to increase the diversity of data by intentionally inserting noise. This method was selected because of the advantage of quickly generating a lot of virtual images and annotation files. Fig. 4 shows the steps used to generate the training data. In the figure, a ‘base’ means the background of the training image, and a ‘material’ means the object to be placed on the base.
因此,本研究采用了一种简单的方法,将物体随机放置在图像上。该方法设计简单,优点是可以同时获得标记数据,因为我们知道物体的位置。然而,由于生成方法的局限性,有必要通过故意插入噪声来增加数据的多样性。该方法具有快速生成大量虚拟图像和注释文件的优点,因此选择了该方法。图4显示了生成训练数据的步骤。在图中,“基础”指的是训练图像的背景,“材料”指的是要放在基础上的物体。
To achieve a high detection accuracy by applying the generated data to train the deep learning model, generating data similar to the actual environment was necessary. Therefore, to collect reference data for generation, labeling was conducted for at least one safety plan for each type of ship. Hence, 15 safety plans were labeled. Table 2 shows detailed information on the safety plan used as reference data. As described later in Section 2.5, the detection window size used in this study is 416px × 416px, which is small compared to the overall drawing. Since the image that enters the detection window is a tiny part of the drawing, it is the expression method of the object, not the line type, that is important for detection. Accordingly, labeling at least one per ship type is for the reference of the class, number of objects, and image size according to the ship type.
为了将生成的数据用于训练深度学习模型以达到较高的检测精度,需要生成与实际环境相似的数据。因此,为收集生成的参考数据,对每一类型船舶至少进行一个安全方案的标注。因此,15个安全计划被标记。表2显示了作为参考数据的安全计划的详细信息。如后面2.5节所述,本研究中使用的检测窗口大小为416px × 416px,相对于整个绘图来说较小。由于进入检测窗口的图像是图纸的一个很小的部分,所以对于检测来说,重要的是物体的表达方法,而不是线的类型。相应地,对每个船舶类型至少标记一个,以便根据船舶类型参考类、对象数量和图像大小。
The next step was to extract the base and material from the labeled safety plan to generate the training data. An example of generating training data using base and material is shown in Fig. 5.
下一步是从标记的安全计划中提取基础和材料,生成训练数据。图5所示为使用基础和材料生成训练数据的示例。
To obtain a base to place the training objects, an empty plan image, in which the part containing the object was removed from the labeling data, was extracted. For a generation, an image (416 px × 416 px) was randomly cropped from the object-removed plan image and used as a base (Fig. 5-(a)).
为了获得放置训练对象的基础,提取了一幅空的平面图像,其中包含目标的部分从标注数据中去除。对于一代,图像(416px × 416px)从对象删除的平面图像中随机裁剪并用作基础(图5-(a))。
Each safety plan has a different set of object classes. Even in the same class, expression of an object could be different, depending on the safety plan designer, as shown in Fig. 6; hence, this should be considered when classifying the class of the object. First, the classes were classified according to IMO classifications. Although the object expression method is different for each plan, objects belonging to the same category were treated as the same class. Images of objects existing in the safety plan were extracted and reclassified according to the IMO classification. This process was repeated for all labeled safety plans and used as the material (see Fig. 5-(b)).
每个安全计划都有一组不同的对象类。即使在同一个类中,根据安全方案设计者的不同,物体的表达也可能不同,如图6所示;因此,在对对象分类时应该考虑到这一点。首先,按照国际海事组织(IMO)的分类方法进行了分类。虽然每个计划的对象表达方法不同,但属于同一类别的对象被视为同一个类。提取安全计划中存在的物体图像,并根据IMO分类方法进行重新分类。对所有已标记的安全计划重复此过程,并用作材料(见图5-(b))。
The next step is the merging of the base and material. The larger the input size used for training, the more information can be provided, which helps to improve the accuracy. However, over a specific size, the accuracy increase rate converges, and the complexity of the deep learning model increases, which extends the training time and hinders the detection speed. Therefore, we trained the object detection model by fixing the input size to 416 px × 416 px. The base was fixed to the corresponding size, and random rotation was added to diversify the data. This process can minimize the overfitting problem of the deep learning model for the training data. While arranging the materials at the base, random scaling of approximately 20% was applied to the material to ensure the robustness of the deep learning model. Finally, after randomly selecting the type, quantity, and position, the material was placed at the base to create an image for training (Fig. 5(c)). By repeating the previously mentioned process, a large amount of training data (training images and an annotation file) can be generated based on each arranged history. As shown in Fig. 7, the created image has an environment similar to that of the real safety plan.
下一步是基础和材料的合并。用于训练的输入尺寸越大,可以提供的信息越多,有助于提高准确性。但是,在特定的规模上,精度增长率收敛,深度学习模型的复杂性增加,延长了训练时间,阻碍了检测速度。因此,我们通过固定输入大小为416 px × 416 px来训练目标检测模型。将基数固定到相应的大小,并加入随机旋转,使数据多样化。该过程可以最大限度地减少深度学习模型对训练数据的过拟合问题。在对基底材料进行排列时,对材料进行约20%的随机缩放,以保证深度学习模型的鲁棒性。最后,随机选择材料的类型、数量和位置后,将材料放置在基底上,生成用于训练的图像(图5(c))。通过重复前面提到的过程,可以根据每个排列的历史生成大量的训练数据(训练图像和注释文件)。如图7所示,创建的图像环境与真实的安全方案环境相似。
In general, when training a deep learning model, the labeled data are divided into training and validation sets. The training set is related to model training, such as updating weights, whereas the validation set is not involved in training and only used to observe the accuracy of the deep learning model for each epoch. However, because the data generated in this study were not actual data, there was a negligible correlation between the training inclination and detection accuracy. The loss for the training set continues to decrease as training continues without affecting the detection accuracy for the real safety plan. Fig. 8 shows the difference between the data distributions commonly used in training and those used in this study. Each deep learning model was trained for various epochs, and epochs showing high accuracy for each model were fixed and used.
一般来说,在训练深度学习模型时,标记数据被分为训练集和验证集。训练集与模型训练有关,如更新权值,而验证集不参与训练,只用于观察深度学习模型在每个epoch的准确性。但是,由于本研究生成的数据不是实际数据,训练倾角与检测精度之间的相关性可以忽略不计。随着训练的继续,训练集的损失会继续减少,而不会影响真实安全计划的检测精度。图8显示了训练中常用的数据分布与本研究中使用的数据分布的差异。每个深度学习模型对不同的epoch进行训练,固定每个模型精度较高的epoch并使用。
2.4 Deep learning model for object detection in the safety plan (深度学习模型用于安全计划中的目标检测)
Objects in the safety plan represent various equipment or devices on the ship and follow the expression method recommended by the IMO regulations. However, depending on the safety plan designer, several differences exist in the expression, as shown in Fig. 6. The human eye can perceive the difference between these expressions; however, it is difficult for computers to distinguish between these features.
安全计划中的物体代表船舶上的各种设备或装置,并遵循国际海事组织规则推荐的表达方法。但是,根据安全方案设计者的不同,表达式存在若干差异,如图6所示。人类的眼睛可以感知这些表情之间的区别;然而,计算机很难区分这些特征。
Deep learning models are specialized in solving these problems because features are extracted from objects through training. In particular, the CNN model is considered promising to extract these features from images (Albawi et al., 2018). Therefore, even if an object is slightly transformed, it can be detected in the same class. This study aimed to classify hundreds of objects; hence, an object detection model based on the CNN model was used.
深度学习模型专门解决这些问题,因为通过训练从对象中提取特征。特别是,CNN模型被认为有望从图像中提取这些特征(alawi等人,2018年)。因此,即使对一个对象进行了轻微的转换,也可以在同一个类中检测到它。这项研究旨在对数百个物体进行分类;因此,我们使用了一个基于CNN模型的目标检测模型。
The object detection model performs regional proposal, localization, and classification steps to predict the location and class of an object, respectively. In this case, the object detection model is divided into the one-stage and two-stage detection models according to the two-step procedure, as shown in Fig. 9.
目标检测模型分别执行区域建议、定位和分类步骤来预测目标的位置和类别。在此情况下,按照两步流程,将目标检测模型分为单步检测模型和两步检测模型,如图9所示。
The one-stage detection model is characterized by performing the classification and localization steps simultaneously and has benefit of a fast detection speed. Representative one-stage detection models include you only look once (YOLO) and single-shot multibox detector (SSD) (Liu et al., 2016).
该单阶段检测模型具有分类和定位步骤同时进行的特点,具有检测速度快的优点。具有代表性的单级检测模型包括you only look once (YOLO)和单次多盒检测器(SSD) (Liu et al., 2016)。
YOLO v3 (Redmon and Farhadi, 2017) is a well-known third version of one-stage YOLO object detection model. It is characterized using a search technique that divides images into grids, and locates and classifies objects in each grid simultaneously to calculate the results. In the two-stage detection model, the regional proposal step that generates proposal boxes and the localization and classification step that predicts the location and class of an object in the boxes are sequentially per-formed. However, the YOLO model is advantageous owing to its faster detection than other models by performing these two processes simultaneously and is mainly used for real-time detection of objects in an image. Therefore, in the field of naval architecture and ocean engineering, this model is often used to detect and track ships in real-time (J. B. Lee et al., 2021). Because the safety plan has a large input size, the time required for detection can be reduced using the YOLO model, which requires relatively less time to detect.
YOLO v3 (Redmon and Farhadi, 2017)是一种著名的单阶段YOLO对象检测模型的第三版。该算法采用一种搜索技术,将图像划分为网格,同时对每个网格中的对象进行定位和分类,计算结果。在两阶段检测模型中,依次执行生成提议框的区域提议步骤和预测框中对象位置和类别的定位分类步骤。而YOLO模型的优点是它可以同时执行这两个过程,比其他模型的检测速度更快,主要用于图像中目标的实时检测。因此,在造船和海洋工程领域,该模型经常被用于实时检测和跟踪船舶(J. B. Lee et al., 2021)。由于安全方案的输入量较大,使用YOLO模型可以减少检测所需的时间,而YOLO模型检测所需的时间相对较少。
The RetinaNet model (Lin et al., 2020) is a one-stage detection model, similar to the YOLO v3 model, and is characterized by improving training efficiency through a new loss function that plays an important role in training. In particular, this loss function shows good training results for cases where the number of objects is small, and the distinction is evident compared with the background. The safety plan occupies a larger part of the background than the object to be detected; thus, using this model may reflect this environment well.
RetinaNet模型(Lin et al., 2020)是一种单阶段检测模型,类似于YOLO v3模型,其特点是通过一种新的损失函数提高训练效率,该函数在训练中发挥重要作用。特别是在目标数量较少的情况下,该损失函数表现出良好的训练效果,与背景的区别明显。安全方案在背景中所占的面积比待检测对象大;因此,使用该模型可以很好地反映这种环境。
The two-stage detection model provides a relatively high accuracy by the regional proposal step that proposes where to look. However, there is a tendency that it is slower than the one-stage detection model. Also, even if the accuracy was high for a specific dataset, there is no evidence that the model showed promising results for safety plans. Therefore, in this study, the two-stage detection model was applied to detect objects in the safety plan, and the results were compared with those of the one- stage detection model.
两阶段检测模型通过提出查找位置的区域建议步骤提供了相对较高的精度。但是,有一种趋势是,它比单阶段检测模型慢。此外,即使对特定数据集的精度很高,也没有证据表明该模型在安全计划方面显示出良好的结果。因此,本研究采用两阶段检测模型对安全计划中的目标进行检测,并将结果与单阶段检测模型进行比较。
The Faster R–CNN model is a two-stage detection model with the region proposal network (RPN), as shown in Fig. 10 (Ren et al., 2017). However, it consumes more time for detection than that consumed by the one-stage detection model due to one additional step. Still, it shows a relatively higher accuracy than that of other models. In contrast to the previous two object detection models, the proposed method shows a higher detection accuracy.
Faster R-CNN模型是一个带有区域建议网络(RPN)的两阶段检测模型,如图10 (Ren et al., 2017)所示。但是,由于多了一个步骤,它比单阶段检测模型消耗更多的检测时间。尽管如此,它仍然比其他模型显示了相对更高的准确性。与前两种目标检测模型相比,该方法具有更高的检测精度。
In this study, YOLO v3, RetinaNet, and Faster R–CNN models were applied and analyzed for the object detection model. In a study similar to ours, Zhao et al. (2019) used various deep learning models. The results of testing them on representative datasets (VOC, COCO) can be seen in each table. We can see that the training data could change the superiority and inferiority of all deep learning models. This study focused on developing object detection methods within the ship safety plan and a training data generation model. Therefore, all models in this study used the models of the original research without changing the learning pa-rameters or other environments for comparison of the applied detection algorithm.
本研究采用YOLO v3、RetinaNet和Faster R-CNN模型对目标检测模型进行分析。在一项与我们类似的研究中,Zhao等人(2019)使用了各种深度学习模型。在代表性数据集(VOC, COCO)上的测试结果可以在每个表中看到。可以看出,训练数据可以改变所有深度学习模型的优劣势。本研究着重于开发船舶安全计划内的目标检测方法及训练数据生成模型。因此,本研究中所有的模型都使用了原研究的模型,在不改变学习参数或其他环境的情况下,对所应用的检测算法进行比较。
2.5 Detection algorithm for the safety plan
The safety plan has an enormous size compared with the target ob-ject. In addition, most of the plans are in PDF and consist of ship drawings with various elements (tables, headings, etc.). In general, there are approximately 60 classes and 800 objects in the safety plan on average, and the ratio of the target object to safety plan is relatively small (less than approximately 0.003%). Therefore, it requires a long time to train the object detection model; thus, the time required for detection increases significantly. Therefore, to pass the safety plan through the deep learning model, conversion and specialized detection processes are required.
与目标物体相比,安全方案的尺寸是巨大的。此外,大多数计划是PDF格式的,由各种元素(表格、标题等)的船舶图纸组成。一般而言,安全计划中平均约有60个类,800个对象,目标对象与安全计划的比例相对较小(小于约0.003%)。因此,训练目标检测模型需要较长的时间;因此,检测所需的时间大大增加。因此,要使安全方案通过深度学习模型,需要进行转换和专门的检测过程。
The safety plan converted to a resolution of 200 DPI varied from approximately 6600 px × 4500 px to 24,000 px × 7400 px depending on the ship type. This image was then provided as an input to the object detection model, where it was readjusted to fit the size for training (416 px × 416 px). Consequently, most of the information in the safety plan was lost; hence, for the detection accuracy, we needed a suitable input method.
安全计划转换为分辨率为200 DPI,根据船舶类型从大约6600px × 4500px到24000px × 7400px不等。然后将该图像作为对象检测模型的输入,在该模型中它被重新调整以适应训练的大小(416px × 416px)。因此,安全计划中的大部分信息都丢失了;因此,为了检测的准确性,我们需要一个合适的输入法。
The first method was to divide the image equally into a size of 416px × 416px, as shown in Fig. 11 (a). The algorithm in this method is simple and the detection speed is fast. However, if an object exists on the dividing edge, it may be detected as two objects or may not be detected.
第一种方法是将图像平均分割为416 px × 416 px大小,如图11 (a)所示。该方法算法简单,检测速度快。但是,如果一个对象存在于分割边缘上,它可能被检测为两个对象,也可能不被检测到。
The second method was to introduce the sliding-window algorithm consisting of a detection window with 416px × 416px that slides over the image. As shown in Fig. 11 (b), this window passes by sweeping the image at regular intervals. The region that enters the window is sequentially inputted into the object detection model. This algorithm increases the detection accuracy because the target object is uncropped. In contrast, when passing at regular intervals, the same object can be detected as different objects; hence, a specific algorithm is required to filter them into a single object.
第二种方法是引入滑动窗口算法,由一个416px × 416px的检测窗口在图像上滑动组成。如图11 (b)所示,该窗口以规则间隔扫描图像通过。将进入窗口的区域依次输入到目标检测模型中。该算法提高了检测精度,因为目标对象是未裁剪的。相反,当以固定的间隔传递时,可以将相同的对象检测为不同的对象;因此,需要一个特定的算法来将它们过滤成单个对象。
We used the NMS algorithm when using the sliding-window algorithm to solve the problem of duplicated detection. The NMS algorithm determines the degree of overlap between each object and removes the remaining object with low reliability of overlapping. Here, reliability refers to the probability that the object existing in the box belongs to the correct class. To use this algorithm, the concept of the intersection of union (IoU) was proposed. The IoU, as shown in Eq. (1), is a measure of the degree of overlap between the bounding boxes of each object.
在使用滑动窗口算法的同时,我们使用了NMS算法来解决重复检测的问题。NMS算法通过确定每个对象之间的重叠程度,去除重叠可靠性较低的剩余对象。这里,可靠性指的是存在于盒子中的对象属于正确类别的概率。为了利用该算法,提出了并集的交集(IoU)的概念。IoU,如公式(1)所示,是每个对象的边界框之间重叠程度的度量。
For instance, if two bounding boxes overlap entirely, the IoU equals to 1, and if there is no overlap, the IoU equals to 0. In this study, the case where the IoU was greater than 0.2, i.e., the overlapped part exceeded 20% of the region occupied by the two boxes, was identified as dupli-cated results. Since there is almost no overlap between objects in the safety plan, we decided to give a low threshold value.
例如,如果两个边框完全重叠,则IoU等于1,如果没有重叠,则IoU等于0。在本研究中,当IoU大于0.2,即重叠部分超过两个盒子所占区域的20%时,被识别为重复结果。由于安全方案中物体之间几乎不存在重叠,所以我们决定给出一个较低的阈值。
Fig. 12 shows the process of applying the NMS algorithm to the safety plan. The NMS algorithm computed the IoU between each other for all the boxes of detection results. If the IoU between the two bounding boxes was greater than 0.2, the algorithm compared the reliabilities of the two boxes. Subsequently, the box with lower reliability was deleted. This process was performed for all bounding boxes in the image to obtain the detection results from which the duplicated objects were removed.
图12给出了NMS算法在安全计划中的应用过程。NMS算法计算所有检测结果框之间的IoU。如果两个边界框之间的IoU大于0.2,则算法比较两个框的可靠性。随后删除了可靠性较低的框。该过程对图像中的所有边界框执行,以获得检测结果,从中去除重复的对象。
3 Applications
3.1 Comparison of the object detection models
Before developing the detection algorithm, we assessed the accuracy of the object detection models by creating an example to select the model to be used. The indicator for comparing the detection accuracy, called Prototype-1, consisted of ten images with 58 objects (10 classes), as shown in Fig. 13. The accuracy rates for object detection models are defined in Eqs. (2)–(4), and the terms are defined in Table 3. Recall refers to the portion of actual correct answers found out of all actual correct answers. On the other side, precision means the ratio of the actual correct answers among those detected as correct answers. Since the two rates tend to be opposite to each other, the F1-score is the harmonic average of the two.
在开发检测算法之前,我们通过创建一个示例来选择要使用的模型来评估目标检测模型的准确性。比较检测精度的指标Prototype-1由10幅图像58个物体(10类)组成,如图13所示。在方程中定义了目标检测模型的准确率。(2) -(4),术语定义见表3。回忆是指在所有实际正确答案中找出的实际正确答案的部分。另一方面,精确度是指实际正确答案与被检测为正确答案的答案的比率。由于两种比率往往是相反的,f1分数是两者的调和平均数。
As shown in Table 4, trained with 10,000 training data equally, the detection accuracy of the RetinaNet model was better than that of the YOLO v3 model; hence, an object detection algorithm was developed using the RetinaNet model. The specifications of the computer used in this study are listed in Table 5.
如表4所示,平均10000个训练数据训练后,RetinaNet模型的检测精度优于YOLOv3模型;因此,我们开发了一种基于RetinaNet模型的目标检测算法。本研究使用的计算机规格如表5所示。
Because the safety plan was tens of times larger than the size of the detection input conducted in other relevant studies, a unique detection algorithm to deal with a large input size was required. Therefore, a detection algorithm that utilized the sliding-window algorithm was applied to the RetinaNet model. To use the sliding-window algorithm, the NMS algorithm for removing duplicated objects was subsequently added. To efficiently track the detection accuracy, the object detection model was evaluated using Prototype-2 (see Fig. 14). Prototype-2 was a bulk carrier safety plan consisting of 723 objects (83 classes), and an accuracy index, called the F1-score, was used. To train the RetinaNet model, 200,000 training data were created and the model with 83 classes was trained.
由于安全方案是其他相关研究检测输入规模的数十倍,因此需要一种独特的检测算法来处理较大的输入规模。因此,将一种利用滑动窗算法的检测算法应用于retina模型。为了使用滑动窗口算法,随后增加了用于移除重复对象的NMS算法。为了高效跟踪检测精度,使用Prototype-2对目标检测模型进行评估(见图14)。原型2号是由723个物体(83个等级)组成的散货船安全计划,使用了被称为f1评分的准确性指标。为了训练RetinaNet模型,创建了20万个训练数据,训练了83个类的模型。
Table 6 shows that when the sliding-window algorithm was applied to the RetinaNet model, the recall was high. However, the number of false or duplicated detection results was more than six times that of the actual number of correct answers, resulting in very low precision. To overcome this problem, the NMS algorithm was applied to every detection window where objects were detected while moving around the image. We could adjust the IoU threshold of the NMS algorithm that RetinaNet owns, but in this study, we used a method of reapplying the NMS algorithm to use the original detection model as it is. Then, the NMS algorithm was used again for the entire results to reduce false detections. Furthermore, by adding a method to designate the detection area before the start, the required time and the number of misdetections could be reduced.
从表6可以看出,将滑动窗口算法应用于视网膜anet模型时,查全率较高。但是,错误或重复的检测结果是实际正确答案数的6倍以上,准确度很低。为了克服这一问题,将NMS算法应用到每个检测窗口,在图像周围移动时检测到物体。我们可以调整RetinaNet所拥有的NMS算法的IoU阈值,但是在本研究中,我们采用了一种重新应用NMS算法的方法来使用原来的检测模型。然后,对整个结果再次使用NMS算法,以减少误检。此外,通过增加在开始前指定检测区域的方法,可以减少所需的时间和误检次数。
There are various objects in the safety plan, and there are cases that do not belong to the classes assigned by IMO classifications or do not follow the expression defined by IMO. To ensure the robustness of the object detection model, it was necessary to deal with the objects belonging only to the IMO classifications. Therefore, to match the pre-viously labeled Prototype-2 to the IMO classifications (a total of 157 classes), the number of objects to be classified was reduced from 723 (83 classes) to 623 (59 classes). Subsequently, by generating 200,000 training data with IMO classifications and retraining the RetinaNet model, the results are shown in Table 7. As the number of classes to be identified increased, the F1-score slightly decreased to 0.63.
安全计划中有各种各样的对象,有不属于国际海事组织(IMO)分类分配的类别或不遵循国际海事组织(IMO)定义的表达的情况。为了保证目标检测模型的鲁棒性,需要对只属于IMO分类的目标进行处理。因此,为了将之前标记的Prototype-2与IMO分类(共157类)相匹配,需要分类的对象数量从723(83类)减少到623(59类)。随后,通过IMO分类生成20万训练数据,再训练RetinaNet模型,结果如表7所示。随着需要识别的班级数量的增加,f1分数略有下降,为0.63分。
As mentioned earlier, the RetinaNet model was tested by adjusting the object detection algorithms, but still showed low detection accuracy for the safety plan. Therefore, the two-stage detection model, the Faster R–CNN model, was trained in the same environment and compared. As shown in Table 8, the time required for detection increased. However, the Faster R–CNN model showed better results in safety plan detection than the RetinaNet model. Therefore, the Faster R–CNN model was selected and joined with the object detection algorithm; consequently, a high F1-score was achieved for Prototype-2.
如前所述,我们通过调整目标检测算法来测试RetinaNet模型,但对安全方案的检测精度仍然较低。因此,我们在相同的环境下训练两阶段检测模型Faster R-CNN模型并进行对比。如表8所示,检测所需时间增加。然而,Faster R-CNN模型在安全计划检测方面比视网膜网模型表现出更好的结果。因此,选择Faster R-CNN模型,并与目标检测算法相结合;因此,原型2获得了较高的f1分数。
3.2 Variation in the training data
Through the analysis, an object detection model was developed using the Faster R–CNN model. To improve the detection accuracy, it was compared by modifying the parameters of the training data generation model. The training data generated according to each parameter are shown in Fig. 15.
通过分析,建立了基于Faster R-CNN模型的目标检测模型。为了提高检测精度,通过修改训练数据生成模型的参数进行比较。根据各参数生成的训练数据如图15所示。
As shown in Table 9, when noise was added, the recall was slightly reduced compared with the case without noise. However, the precision increased significantly. In addition, when scaling was applied to the material of the training data, it showed the best F1-score compared with the other parameters. Therefore, we inserted noise into the base and applied size scaling to the material during generation.
如表9所示,当添加噪声时,召回率比不添加噪声时略有降低。然而,精确度显著提高。此外,当对训练数据的材料进行缩放时,与其他参数相比,f1得分最好。因此,我们在基底中插入噪声,并在生成过程中对材料进行尺寸缩放。
Next, the undetected object was analyzed to further improve the accuracy of the object detection model. In Fig. 16, the object was not detected owing to the different size of the object in the detection area and training data. When training the object detection model, large ob-jects were rarely detected because training data consisted of small ob-jects only. Therefore, the scaling ratio and primary size of object were increased (from 60 px ± 20% to 80 px± 30% px), and F1-score of 0.90 was achieved for object detection for Prototype-2. However, because this was an unreliable accuracy indicator owing to the use of a single safety plan, it was necessary to obtain the general accuracy for various safety plans.
其次,对未检测到的目标进行分析,进一步提高目标检测模型的精度。在图16中,由于检测区域和训练数据中物体的大小不同,所以没有检测到目标。在训练对象检测模型时,由于训练数据中只有小对象,所以很少能检测到大对象。因此,提高了物体的缩放比和原始尺寸(从60 px±20%提高到80 px±30% px), Prototype-2的物体检测f1得分为0.90。然而,由于使用单一的安全计划,这是一个不可靠的精度指标,因此有必要获得各种安全计划的一般精度。
Therefore, 15 types of safety plan data, listed in Table 2, were used to determine the accuracy of the object detection model. A few of the safety plans that were used are shown in Fig. 17. The accuracy of the object detection model was calculated using the average object detection ac-curacy for each safety plan. Although 15 plans may seem insufficient, we can regard them as a large number of test data because the detection window size is 416 px × 416 px. From the point of view of the detection window, detection proceeds for 10,000 objects in about 30,000 images.
因此,我们使用表2所示的15类安全计划数据来确定目标检测模型的准确性。一些使用的安全方案如图17所示。使用每个安全计划的平均目标检测精度来计算目标检测模型的精度。虽然15个方案看似不够,但由于检测窗口大小为416 px × 416 px,我们可以将其视为大量的测试数据。从检测窗口来看,大约3万张图像中有1万个物体进行检测。
When comparing the accuracy of the Faster R–CNN model using the aforementioned method, the average recall for the 15 safety plans was 0.55, as shown in Fig. 18 (a) and Table 10. It is noteworthy that the F1- score of some safety plans significantly lowered the average recall.
在使用上述方法比较Faster R-CNN模型的准确性时,15个安全方案的平均召回率为0.55,如图18 (a)和表10所示。值得注意的是,一些安全计划的F1-得分显著降低了平均召回率。
Therefore, we analyzed the factors that reduced the accuracy by comparing the detection results of the safety plans. Fig. 19 shows a photograph of the safety plan at the same magnification. It was observed that the size of the objects in the lowest three recalls is approximately twice as large. Because there were different sizes of objects in various types of plans, we needed to reflect this diversity in the training data. Thus, the size of the objects was applied more diversely than before, as shown in Fig. 18 (c). Consequently, the average recall increased from 0.55 to 0.67, as shown in Fig. 18 (b). However, as the size of the training object was diversified, the precision decreased drastically and the F1- score was lowered, as shown in Table 10.
因此,我们通过比较安全方案的检测结果,分析了降低准确性的因素。图19显示了相同放大倍率下的安全方案照片。我们观察到,在最低的三次召回中,对象的大小大约是前者的两倍。因为在不同类型的计划中有不同大小的对象,我们需要在训练数据中反映这种多样性。因此,对训练对象大小的应用比以前更加多样化,如图18 (c)所示。因此,平均召回率从0.55增加到0.67,如图18 (b)所示。然而,随着训练对象大小的多样化,精度急剧下降,F1-得分下降,如表10所示。
The significant improvement in recall for some safety plans showed that the object detection model was well trained. However, a significant drop was observed in recall for other safety plans; this might be due to the characteristics of each safety plan. Therefore, we analyzed the size of the object in the detection window, as shown in Fig. 20.
一些安全计划召回率的显著提高表明目标检测模型得到了很好的训练。然而,其他安全计划的召回量明显下降;这可能是由于每个安全计划的特点。因此,我们对检测窗口内物体的大小进行了分析,如图20所示。
Fig. 20 shows a comparison of the size of objects between the training data and detection area of the safety plan, which has the lowest F1-score. Although the size of objects in the training data was diversified as much as possible at the same magnification, a significant difference in size was still observed. However, there was a limitation to diversifying object size because the probability of false detection increases (i.e., lowering the precision) as the sizes of more objects are reflected. Therefore, rather than modifying the generation model for the training data, predesignating the magnification of the detection window according to the safety plan could solve this problem. Because the average size of objects was different for each safety plan, the magnification of the detection window was adjusted by separately designating the average size of the object before starting object detection. With this modification, the average accuracy was calculated again for these 15 safety plans. Consequently, the average recall significantly increased from 0.67 to 0.85, as shown in Fig. 18 (d) and Table 10. It is noteworthy that the standard deviation of the recall decreased with the increasing material size distribution. However, precision tended to be lower than that of recall. This tendency was mostly caused by differences in object expression among the safety plans and diversity of object classes.
图20是训练数据与安全方案检测区域的对象大小对比,其中f1得分最低的安全方案检测区域的对象大小比较。尽管在相同的放大倍率下,训练数据中物体的大小是尽可能多样化的,但仍然观察到显著的大小差异。然而,多样化的对象大小是有限制的,因为当更多的对象的大小被反映出来时,错误检测的概率会增加(即降低精度)。因此,与其修改训练数据的生成模型,不如根据安全计划预先指定检测窗口的放大倍数,可以解决这一问题。由于每个安全方案的物体平均大小不同,在开始物体检测之前,通过分别指定物体的平均大小来调整检测窗口的放大倍数。经过修改后,再次计算这15个安全方案的平均精度。因此,平均召回率从0.67显著提高到0.85,如图18 (d)和表10所示。值得注意的是,召回率的标准差随着物料粒度分布的增大而减小。然而,准确率往往低于召回率。这一趋势主要是由于安全方案之间对象表达的差异和对象类的多样性造成的。
4 Conclusions and future works
This study proposed an object detection model for ship safety plans. By comparing the object detection models, the Faster R–CNN model that showed the best accuracy was selected. To detect an enormous area of a safety plan, we proposed a specialized object detection algorithm for safety plans by combining the sliding window and NMS algorithms. It is difficult to obtain training data because labeling is time consuming and labor intensive. Therefore, we proposed a method that automatically generates numerous training data and trains the object detection model. For 15 actual safety plans, the average F1-score was 0.72. Because the model showed good performance even when using the generated training data, this study indicated that it can solve the insufficient labeling data problem. In addition, we succeeded in finding more than 85% of the objects for two-thirds of the 15 safety plans. Therefore, it is expected that the method proposed in this study will assist in the efficient inspection of safety plans.
本文提出了一种船舶安全计划的目标检测模型。通过比较目标检测模型,选择了准确率最好的Faster R-CNN模型。为了检测安全计划的大面积区域,结合滑动窗口和NMS算法,提出了一种专门的安全计划对象检测算法。由于贴标签费时费力,训练数据难以获取。因此,我们提出了一种自动生成大量训练数据的方法,对目标检测模型进行训练。在15个实际安全计划中,f1得分平均为0.72。由于该模型在使用生成的训练数据时表现出良好的性能,本研究表明它可以解决标记数据不足的问题。此外,在15个安全方案中,我们成功地找到了超过85%的目标。因此,预计本研究中提出的方法将有助于有效地检查安全计划。
In the future, further research is recommended to obtain higher accuracy. Because the object detection model was trained only with the generated training data, the parameters of the generation model significantly influenced the detection accuracy. Therefore, a quantitative comparison is recommended for each parameter. In the review task, finding the actual correct answer as many as possible is related to recall, so this study focused on improving recall performance. On the other hand, to increase precision related to the reduction of misrecognition, it is necessary to reflect various environments in the training data. The precision and F1-score may be increased through careful parameter control, such as by adjusting the size of the material. The average detection accuracy for the 15 safety plans was used as the accuracy indicator in this study; hence, it is necessary to increase the reliability of the accuracy indicator by labeling more safety plans. Also, because labeling quality differs according to the labeler, an additional review process is recommended for future studies.
今后,建议进一步研究以获得更高的精度。由于目标检测模型只使用生成的训练数据进行训练,因此生成模型的参数对检测精度有显著影响。因此,建议对每个参数进行定量比较。在复习任务中,找出尽可能多的实际正确答案与回忆相关,因此本研究的重点是提高回忆性能。另一方面,为了提高与减少误识别相关的精度,需要在训练数据中反映各种环境。通过精心的参数控制,例如通过调整材料的尺寸,可以提高精度和f1分数。本研究以15种安全方案的平均检测精度作为准确性指标;因此,有必要通过标注更多的安全方案来增加精度指标的可靠性。此外,因为标签的质量根据标签商的不同而不同,建议对未来的研究进行额外的审查过程。
Besides the training data generation model, the object detection method also needs improvement. This study used three well-known models (YOLO v3, RetinaNet, and Faster R–CNN) among the one-stage and two-stage detection models. Recently, models such as a fully convolutional one-stage (FCOS) object detection model (Tian et al., 2019) and YOLO v5 (Jocher et al., 2020) exceeded the performance of these models have emerged. Therefore, we plan to continuously improve detection accuracy and inference time by using the latest model above. Despite almost no overlap between objects in the safety plan, overlap still exists in the overall detection result because the sliding-window algorithm is applied. The NMS algorithm was used to delete the over-lapped low-confidence bounding box. The Soft-NMS (Bodla et al., 2017) algorithm lowers the reliability of the corresponding box without removing the box. Therefore, it is expected to obtain better results when applied to further research. This study will be continuously improved by considering the parameters of the generation model and the latest detection methods.
除了训练数据生成模型,目标检测方法也有待改进。在单阶段和两阶段检测模型中,本研究使用了三个比较知名的模型(YOLO v3、视网膜anet和Faster R-CNN)。最近出现了一些模型,如全卷积单阶段(FCOS)目标检测模型(Tian等人,2019)和YOLO v5 (Jocher等人,2020),其性能超过了这些模型。因此,我们计划使用上述最新模型来不断提高检测精度和推断时间。虽然安全方案中的目标之间几乎没有重叠,但由于采用了滑动窗口算法,整体检测结果仍然存在重叠。采用NMS算法删除重叠的低置信度边界框。Soft-NMS (Bodla et al., 2017)算法在不移除盒子的情况下降低了对应盒子的可靠性。因此,当它应用于进一步的研究时,有望获得更好的结果。本研究将结合生成模型的参数和最新的检测方法不断完善。
.jpg)