.jpg)
Paper Reading 7|An Image-Based Benchmark Dataset and a Novel Object Detector for Water Surface Object Detection
摘要
水面物体检测是自动驾驶和水面视觉应用的重要课题之一。迄今为止,从网站收集的现有公共大规模数据集并不关注具体的场景。作为这些数据集的一个特点,图像和实例的数量也仍然处于较低的水平。为加快水面自动驾驶技术的发展,本文提出了一个大规模、高质量的标注基准数据集——水面物体检测数据集(WSODD),用于对不同的水面物体检测算法进行基准测试。该数据集包含7467张不同水环境、气候条件和拍摄时间的水面图像。此外,该数据集包括14个公共对象类别和21,911个实例。同时,在WSODD中还关注更具体的场景。为了找到在WSODD上提供良好性能的简单的体系结构,提出了一种名为CRB-Net的新的对象检测器作为基线。在实验中,CRB-Net与16种最先进的物体检测方法进行了比较,在检测精度上都优于它们。在本文中,我们进一步讨论了数据集多样性(例如,实例大小、光照条件)、训练集大小和数据集细节(例如,分类方法)的影响。跨数据集验证表明,WSODD的性能明显优于其他相关数据集,CRB-Net具有良好的适应性。
引言
水面物体检测在无人驾驶水面车辆(usv)和水面视觉应用等自动驾驶领域发挥着越来越重要的作用。为了更准确地检测视觉对象,使用带注释的基准数据集(Everingham等人,2010)来验证不同的对象检测方法,可以避免建立自己的数据集的耗时过程。根据不同的对象检测方法,可以基于相同的标注基准数据集给出有说服力的性能比较。然而,关注水面物体检测应用的基于图像的数据集缺乏。此外,目前的水面数据集还存在一些缺陷。例如,船型识别数据集(Clorichel, 2018)中存在的主要问题是数据规模小,水面物体类别数量有限,而且只有一种气候类型。此外,对于大型的基于图像的通用数据集,如MS COCO (Lin et al., 2014)、ImageNet (Krizhevsky et al., 2012)和Places 2 (Zhou et al., 2015),水面视觉对象的图像来自网站,没有足够的图像来训练不同的神经网络。因此,当水面探测器对这些类型的数据集进行训练时,性能是一个问题。为了解决这些问题,有必要建立一个新的水面数据集,包含广泛的水环境、完整的常见障碍类别、多种气候条件和不同的拍摄时间。
本文提出了一个新的基准数据集WSODD,它具有更多的实例和类别,用于水面常见障碍的检测。它由7467张由海康威视工业相机拍摄的水面图像组成,每张图像的分辨率是1920 × 1080。WSODD中包含了各种各样的环境,如海洋、湖泊和河流。WSODD中的图像是在三种不同的拍摄时段(白天、黄昏和夜晚)和三种不同的气候条件(晴天、多云和雾天)下获得的。在提议的全注释数据集中,有14个类别和21,911个实例,每个实例都用轴对称边界框标记。所有的注释和原始图片都将公开,并将建立一个在线基准。
为了深入研究WSODD,建议将CRB-Net作为基线。水面物体检测数据集(WSODD)包含许多小的物体以及不容易被检测到的物体,因此检测器提取更深层次的语义特征,并使用SPP (He et al., 2015)来增强接受野。虽然融合了跨尺度的特征,但大多数以前的结构只是简单的堆叠输入,没有区别。然而,这些特征具有不同的分辨率,它们对融合特征的贡献往往是不相等的。为了解决这一问题,我们引入了一种改进的BIFPN (Tan等人,2020),它可以在特征融合过程中通过注意机制和Mish激活进行自适应权重调整(Misra, 2019)。此外,CRB-Net基于K-means算法优化锚帧初值,使锚帧符合障碍物的形状特征。本文的主要贡献是:
(1) 水面物体检测数据集是一种基于图像的新型水面物体检测基准数据集,具有最多的常见障碍类别、最广泛的水环境和天气条件。WSODD中的图像能更准确地反映真实的视觉对象。
(2) 提出了一种新的目标检测方法(CRB-Net),并与16种最先进的目标检测方法进行了性能比较。结果表明,CRB-Net在检测精度方面优于其他方法。此外,我们还探索了各种探测器对WSODD中不同大小物体的检测性能。
(3) 选择船型识别数据集进行跨数据集泛化,因为该数据集是唯一公开的基于图像的水面数据集。结果表明,WSODD比船型识别具有更多的模式和属性,CRB-Net具有较好的泛化能力。
除了推进水面视觉中的物体检测研究外,WSODD还将提出机器视觉领域中值得探索的方法的新问题。
相关工作
数据集
目前,用于水面物体检测的数据集并不多。船型识别数据集是该领域唯一的基于公共图像的数据集。它包含1462幅水面图像,有三类常见的物体:船(贡多拉、充气船、皮划艇、纸船、帆船)、船(游轮、渡船、货船)和浮标。虽然该数据集的水环境和拍摄时间非常丰富,但在数据集中没有提供对象检测的注释。
基于图像的通用数据集也可用于水面检测。例如,MS COCO是一个大型通用数据集,包括91类对象,总共328,000张图像。然而,与水面检测相关的只有一个类别(船),包含3146张图像。显然,该数据集中的障碍和图像数量不足以保证深度学习神经网络的有效训练。另一个名为ImageNet的数据集提供了大规模的注解,但与水面物体检测相关的类别只有四种:双体船、三体船、集装箱船和航空母舰,这些图像与真实的水面情况有很大的差异。此外,Places2是一个泛型数据集,包含365个类别,但只有5个类别与水面有关,分别是港口、湖泊、装卸区、水和河流。一般来说,由于缺乏水面障碍物,这些图像大多无法用于水面目标检测任务。表1显示了WSODD与其他基于图像的WSODD的比较。
此外,也有一些基于视频的wsodd,如新加坡-海事数据集(Prasad et al., 2017)、MODD数据集(Kristan et al., 2016)和Visual-Inertial-Canoe数据集(Miller et al., 2018),但大多数都存在障碍类别少、环境相对简单的问题,难以实现较好的目标检测性能。
方法
众所周知,对于早期的通用对象检测方法[例如,LBP (Ojala等人,2002),DPM (Felzenszwalb等人,2010)],很难从图像中提取特征。此外,目标检测的精度和速度也不能令人满意。2012年以后,随着深度学习的发展,出现了许多基于cnn的高效检测器,主要分为两类:两阶段目标检测方法和一级目标检测方法(Liang et al., 2020)。最著名的两阶段目标检测方法是R-CNN (Girshick等人,2014)系列[例如,Faster R-CNN (Ren等人,2016),Mask R-CNN (He等人,2017)和Cascade R-CNN (Cai和Vasconcelos, 2018)]。在单阶段目标检测方法方面,Yolo (Redmon and Farhadi, 2018)和SSD (Liu et al., 2016)是最显著的方法。此外,一级检测器还可以转化为CenterNet等无锚检测器(Duan et al., 2019)。
水面目标检测作为计算机视觉的重要组成部分,受到了广泛关注。在深度学习方法出现之前,小波变换与图像形态学相结合的方法(Yang et al., 2004)是实现水面目标检测的主导方法。提出了一种基于HOG (Dalal and Triggs, 2005)的目标检测系统(Wijnhoven et al., 2010),用于在海上视频中寻找船舶。Matsumoto (Matsumoto, 2013)提出了一种HOG-SVM方法,用于在舰船摄像机图像上检测舰船。Kaido等在2016年将支持向量机和边缘检测用于舰船的检测。此外,通过使用两个摄像头和对通过港口的各种船舶的识别,提出了船舶号牌识别(Kaido等人,2016年)。
深度学习技术极大地推动了该领域的发展。由于尺寸、外观和干扰的变化,无监督方法(Liu et al., 2014)受到严重限制。因此,使用监督方法更为常见(Mizuho等人,2021年)。Yang (Yang et al., 2017)提出了一种使用Fast R-CNN实现船舶识别和分类的体系结构。此外,提出了一种集成了深度学习方法的混合舰船检测方法(Yao et al., 2017)。具体来说,他们利用深度神经网络(DNNs)和区域提议网络(RPNs)获取目标船只的2D边界框。此外,设计了一种基于ResNet的地表物体快速检测方法(Chae et al., 2017),目标检测速度可达32.4帧/秒(FPS)。此外,Qin (Qin and Zhang, 2018)采用FCN进行表面障碍检测,具有良好的鲁棒性。2019年,提出了一种改进的基于rbox的水面目标检测框架(an et al., 2019),以获得检测的精度召回率和精度。Sr等人提出了一种利用改进的YOLO和多特征舰船检测方法对舰船进行检测的舰船算法。该方法通过MDS(多维尺度)对SIFT特征进行降维,并使用RANSAC(随机样本一致性)优化SIFT特征匹配,有效消除不匹配(Sr等,2019)。此外,提出了一种基于改进的Faster R-CNN的实时水面物体检测方法(Zhang et al., 2019),该方法包括两个模块,将低层特征与高层特征相结合,提高检测精度。利用该方法对北京北运河的水面浮子进行了3天的视频监控,验证了该方法的有效性。此外,采用深度残差网络和跨层跳转连接策略(Liu et al., 2019)提取先进的船舶特征,有助于提高目标识别性能。2020年,基于yolov2 (Chen et al., 2020b)提出了一种检测小船的方法,该方法还可以用于识别水面上的各种障碍物。H-Yolo (Tang et al., 2020)提出了基于兴趣区域预选网络的船舶检测。该方法的原理是根据船舶与背景之间的色相、饱和度、值(HSV)差异从图像中区分可疑区域。然后,提出了一种名为Yolov3-2SMA的水面检测方法(Li et al., 2020),允许在动态水中环境中实时、高精度的物体检测。此外,Jie等人(2021)改进了yolov3用于检测内河水道中的船舶,改进方法的mAP和FPS分别提高了约5%和2%。最近,造船厂(Han et al., 2021)被引入来解决小型船舶的漏检问题。该算法设计了一种新的扩展卷积和最大池化放大接受场模块,提高了模型对空间信息的获取能力和目标空间位移的鲁棒性。然而,上述大多数方法都是基于用于港口管理的静态摄像机的自主船舶上不可行,因此与移动自主船舶上的舰载监视系统不匹配(Jie等人,2021年)。此外,即使所有提出的算法都存在效率和准确性方面的缺陷。
水面物体检测的基准数据集
大多数研究人员认为,一个数据集应该涵盖尽可能多的真实图像,在注释过程中尽可能少的个人偏见。与以往的数据集相比,本文提出的数据集包含了更多的实例、类别、环境、拍摄时间和天气条件。
图像采集
WSODD中的所有图像都是由一台工业4G高清相机在2020年7月16日至9月10日期间拍摄的。温度范围为20-35◦C。
为了丰富环境,尽可能准确地反映现实世界,我们选择了五个水域,包括三种类型的水面环境。这些是渤海(中国辽宁省的大连;海洋),黄海(中国山东省烟台市;海洋),玄武湖(江苏省南京市,中国;南海子湖(北京,中国;湖泊)和长江(中国江苏省南京市;河)。
为了丰富气候类别,每一个水环境都在不同的天气条件下拍摄,如阳光、云层和雾。
同时,在不同的光照条件下,包括正午(强光)、黄昏(弱光)和晚上(极弱光)对障碍物进行拍摄,以便为数据集收集足够的研究材料。
图1显示了WSODD的一些典型环境。可见,这些图像不仅显示了大量的水面障碍物信息,还包含了周边海域、陆地和港口的相关信息,更接近于实际的水面物体检测应用(Kristan et al., 2014)。
选择的类别
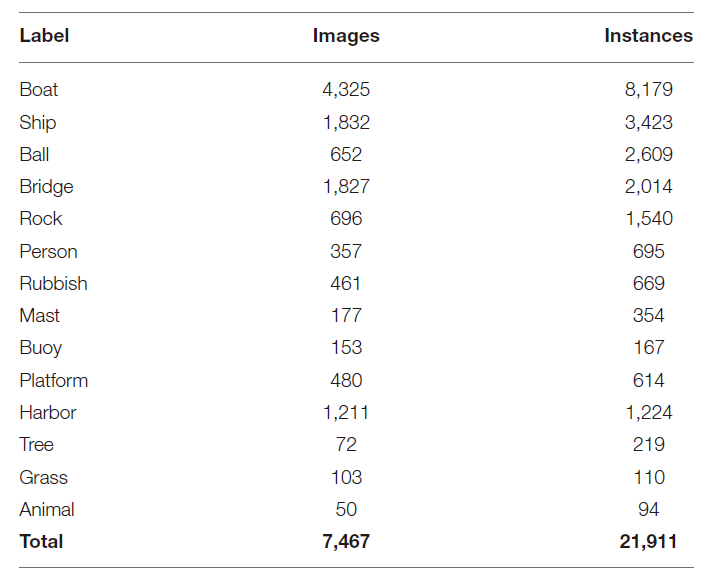
选取水面物体检测数据集,对水面上常见的14个物体进行标注,分别是船、船、球、桥、岩石、人、垃圾、桅杆、浮标、平台、港口、树、草、动物。图2显示了每个类别的两个图像。
选择对象的核心标准是其在真实水环境中的共性。水面物体检测数据集的对象类别划分比较广泛。例如,船舶类别包括大型军舰和客轮;与此同时,其他研究人员可以直接基于这个数据集测试方法,或者对现有的类别进行更详细的分类。表2列出了WSODD的每个类别的映像和实例的数量。
图像标注
水面物体检测数据集有两种注释方式,与PASCAL VOC (Everingham等人,2010)和MS COCO (Lin等人,2014)相同。注释文件以XML格式保存。
考虑到很多研究者基于COCO格式注释文件进行实验,我们将提供将VOC文件转换为COCO文件的代码。当其他研究人员想要使用COCO格式注释文件时,他们可以使用此代码轻松地转换格式。
值得注意的是,这项研究关注于注解水面数据集,而不包括陆地对象。所有的注释,包括省略的对象,都由工程师检查,以确保更详细的注释。
数据集的统计数据
不同水面环境的统计结果如图3所示。海洋环境图像1771张,湖泊环境图像4114张,河流环境图像1581张,分别占WSODD的24%、55%和21% (Zhang et al., 2020)。需要注意的是,WSODD中的船舶类别只包括海洋和河流,因为玄武湖和南海子湖是小湖,不能容纳大型船舶。平台类只存在于海中。在拍摄过程中,我们发现在近海水域有很多这样的平台,用于海洋养殖和海水质量检测,但在河流和湖泊中没有发现这样的物体。相反,草的分类只存在于河流和湖泊中,而不存在于海中,那里从未发现过大面积的草。一个可能的原因是海浪的冲击会破坏草的生长。
图4描述了不同气候条件下的图像数量。大部分图像(4918张,占WSODD的66%)是在晴天拍摄的,而最少的图像(589张,占数据集的8%)是在雾天拍摄的。
不同拍摄时间的数据如图5所示。大部分照片,6354张,约占总数的85%,是在白天收集的。此外,每张照片平均在白天拍摄3.15个实例。黄昏时的每张图像都拍摄了类似数量的实例,为3.24个(Alessandro et al., 2018)。然而,每张在夜间拍摄的照片的平均实例数是1.19。造成这种巨大差异的主要原因有两个。一是在夜间继续移动的物体数量很少,比如船只。二是夜间光线太暗,很多已有的物体无法被发现,特别是距离拍摄地点较远的物体或较小的物体。
一些实例可能只有图像的0.01%,而另一些实例可能超过40%。实例之间的显著差异使检测任务更加具有挑战性,因为模型必须足够灵活,以便处理极小和极大的对象(Li et al., 2018)。图6描述了映像中实例规模的统计信息。
水面物体的新型探测器
为了构建WSODD的基线方法,我们提出了CRB-Net,这是一种基于CSPResNet的增强目标检测器(Wang et al., 2019
网络结构
图7显示了CRB-Net的体系结构。CRB-Net的主干使用ResBlock_building块获得5个输出特征层,每个特征层中的特征点设置为3个锚点。
此外,每个检测层的每个检测帧基于不同的锚帧进行偏移。每个锚的宽度和高度值需要根据被检测物体的形状特征来获得。我们使用K-means聚类算法对锚帧的初始值进行优化,使锚帧更适合水面场景,同时显著减少了训练时间。
接下来,使用两个SPPNets (He et al., 2014)来增加F4和F5的接受域,这两个域可以分离出最重要的上下文特征。
融合不同分辨率功能的常用方法是,在将它们相加之前,将它们的分辨率调整为相同的大小。然而,不同的输入对融合过程的贡献是不一样的。为了解决这个问题,我们设计了一个改进的BIFPN,它包含了一个注意机制。
最后,将语义融合后的特征层分别送入5个Yolo头部,得到预测结果。
网络模块详细信息
ResBlock_Body
这实际上是一个CSPResNet,其结构如图8所示。剩余块堆叠在主干部分。另一部分,残边,经过一些处理后直接连接到末端。这种结构缓解了DNN深度增加引起的梯度消失问题。
K-Means Algorithm
为了寻找最优的聚类效果,我们选取了多组不同数量的聚类进行实验比较。我们发现,当聚类数量达到15个时,平均欠条的增长几乎停止(平均欠条的计算方法是计算每个训练集标签的欠条和聚类得到的中心,以最大的欠条值作为该标签的值,最后将所有标签值平均得到)。考虑到模型过拟合的风险会随着聚类数量的增加而增加,最终选取了15个聚类中心。
改进的BIFPN
它集成了双向跨尺度连接和快速归一化融合。选择最佳值1.35作为BiFPN宽度缩放因子。为了更好的说明融合的过程,选择P2作为一个例子来描述融合的特征。
此外,CRB-Net使用以下方案:CutMix (Yun等人,2019)、DropBlock正则化(Ghiasi等人,2018)、ciou损失(Zheng等人,2020)、CmBN (Yao等人,2020)和NMS (Bodla等人,2017)。我们尝试使用马赛克数据增强(Bochkovskiy等人,2020年)、类标签平滑(Szegedy等人,2016年)和余弦退火调度器(Loshchilov和Hutter, 2016年),但这些方案都没有很好地工作。
实验和讨论
目标检测的目的是准确识别图像中各种目标的类别和位置信息。
.png)
.jpg)