.jpg)
YOLOv5学习笔记2
Yolov5学习笔记2——代码框架
打开Yolov5的代码,可以看到有许多文件夹和很多的子文件。本文主要弄清楚Yolov5的代码框架。
data文件夹
该文件夹下主要存放项目运行所需要的数据,包括一些超参、默认输入的图片等。
hyps文件夹
该文件夹下存放的都是训练参数
hyp.Objects365.yaml——项目在进行Objects365训练的超参数。hyp.scratch-high.yaml——里面的参数为对COCO数据集从零开始进行高增强训练的超参数。hyp.scratch-low.yaml——对COCO数据集从零开始进行低增强训练的超参数。hyp.scratch-med.yaml——对COCO数据集从零开始进行中等增强训练的超参数。hyp.VOC.yaml——对VOC数据集进行训练时的超参数。
一般这些参数都不需要改动,这是作者团队大量训练记录的最好的参数结果。
images文件夹
该文件夹下存放了代码默认执行detect.py时检测的图片,执行后会在目录中新建一个runs文件夹并将检测的结果存放在/runs/detect文件夹下。
scripts文件夹
脚本文件夹。提供了下载权重文件夹、COCO数据集、COCO128数据集的方法。直接执行该脚本文件就可以直接下载yolov5x.pt文件和训练的数据集。
注意:如果想要运行脚本文件的话,首先要确定PyCharm有没有安装PowerShell平台,一般PyCharm会提示你安装的。
当然我还是比较推荐直接从github官网中下载。而数据集当然是自制。
其他.yaml文件
这些文件主要是对一些数据集做一个补充说明。如存放的路径、训练的路径、测试的路径等,以及这些数据集有多少张图片,定义了多少个类别等。当然代码中也写了下载这些数据集的方法。
Argoverse.yaml——Argo AI提供的Argoverse-HD数据集(环形前置中央摄像头)coco.yaml——由微软提供的COCO 2017数据集,网址为:http://cocodataset.orgcoco128.yaml——由作者所在公司Ultralytics提供的COCO128数据集(来自COCO train2017的前128张图片),网址为:https://www.kaggle.com/ultralytics/coco128GlobalWheat2020.yaml——由萨斯喀彻温大学提供 全球小麦2020数据集网址为:http://www.global-wheat.com/Objects365.yaml——提供了365个检测对象的数据集,几乎涵盖了生活中的各种常见物体。SKU-110K.yaml——由Trax retail提供的SKU-110K零售项目数据集网址为:https://github.com/eg4000/SKU110K_CVPR19VisDrone.yaml——由天津大学提供的VisDrone2019-DET数据集(无人机拍摄的图片)https://github.com/VisDrone/VisDrone-DatasetVOC.yaml——由牛津大学提供的PASCAL VOC数据集http://host.robots.ox.ac.uk/pascal/VOCxView.yaml——由美国国家地理空间情报局(NGA)提供的DIUx xView 2018挑战赛中的数据集。https://challenge.xviewdataset.org
model文件夹——模型文件
在本文件夹中主要存放了各种Yolo算法的模型文件。在这些模型文件中定义了如下参数:
| 参数 | 解释 |
|---|---|
| nc | 训练和检测的类别数量 |
| depth_multiple | 网络深度 |
| width_multiple | 网络宽度 |
| anchors | 锚点框参数 |
| backbone | 骨干网络参数 |
| head | 检测头 |
下面以yolov5s.yaml为例,对里面的相关参数进行详细解释。
.yaml介绍
- YAML(YAML Ain`t Markup language)文件, 它不是一个标记语言。配置文件有xml、properties等,但 **YAML是以数据为中心 **,更适合做配置文件。
- YAML的语法和其他高级语言类似,并且可以 简单表达清单、散列表,标量等数据形态。
- 它使用 **空白符号缩进 **和大量依赖外观的特色,特别适合用来表达或编辑数据结构、各种配置文件、倾印调试内容、文件大纲。 yaml介绍
- 大小写敏感;缩进不允许使用tab,只允许空格;缩进的空格数不重要,只要相同层级的元素左对齐即可;’#’表示注释;使用缩进表示层级关系。
注意,在yaml文件中空格数其实也是重要的!在建立YAML 对象时,对象键值对使用冒号结构表示 key: value, 冒号后面要加一个空格。
parameters
1 | # Parameters |
- nc: 类别数,你的类别有多少就填写多少。从1开始算起,不是0-14这样算。
- depth_multiple:控制 模型的深度。
- width_multiple:控制 卷积核的个数。
**depth_multiple **是用在 **backbone **中的 **number≠1的情况下, **即在Bottleneck层使用,控制模型的深度,yolov5s中设置为0.33,假设yolov5l中有三个Bottleneck,那yolov5s中就只有一个Bottleneck。
因为一般 **number=1 **表示的是 **功能背景的层 **,比如说下采样Conv、Focus、SPP(空间金字塔池化)。
——————————————————————————————————————
**width_multiple **主要是用于设置arguments,例如yolov5s设置为0.5,Focus就变成[32, 3],Conv就变成[64, 3, 2]。
以此类推,卷积核的个数都变成了设置的一半。
yolov5提供了s、m、l、x四种,所有的.yaml文件都设置差不多,只有上面2和3的设置不同,作者团队很厉害,只需要修改这两个参数就可以调整模型的网络结构。
anchors
1 | anchors: |
首先,anchor box就是从训练集中真实框(ground truth)中统计或聚类得到的几个不同尺寸的框。避免模型在训练的时候盲目的找,有助于模型快速收敛。假设每个网格对应k个anchor,也就是模型在训练的时候,它只是会在每一个网格附近找出这k种形状,不会找其他的。
anchor其实就是对预测的对象范围进行约束,并加入了尺寸先验经验,从而实现多尺度学习的目的。
而对于yolov5l来说,输出为3个尺度的特征图,分别为13×13、26×26、52×52,对应着9个anchor,每个尺度均分3个anchor。
最小的13×13的特征图上由于其感受野最大,应该使用大的anchor(116x90),(156x198),(373x326),这几个坐标是针对原始输入的,即416×416的,因此要除以32把尺度缩放到13×3下使用,适合较大的目标检测。中等的26×26特征图上由于其具有中等感受野故应用中等的anchor box (30x61),(62x45),(59x119),适合检测中等大小的目标。较大的33×23特征图上由于其具有较小的感受野故应用最小的anchor box(10x13),(16x30),(33x23),适合检测较小的目标。具体使用就是每个grid cell都有3个anchor box。
根据检测层来相应增加anchors。
backbone
1 | backbone: |
- Bottleneck 可以译为“瓶颈层”。
- from列参数: -1代表是从上一层获得的输入 , -2表示从上两层获得的输入 (head同理)。
- number列参数: 1表示只有一个,3表示有三个相同的模块。
- SPPF、Conv、Bottleneck、BottleneckCSP的代码可以在
./models/common.py中获取到。 - [64, 6, 2, 2]解析得到[3, 32, 3] ,输入为3(RGB),输出为32,卷积核k为3;
- [128, 3, 2]这是固定的,128表示输出128个卷积核个数。根据[128, 3, 2]解析得到[32, 64, 3, 2] ,32是输入,64是输出(128×0.5=64),3表示3×3的卷积核,2表示步长为2。
- 主干网是图片从大到小,深度不断加深。
args这里的输入都省去了,因为输入都是上层的输出。为了修改过于麻烦,这里输入的获取是从./models/yolo.py的def parse_model(md, ch)函数中解析得到的。
head
head检测头:一般表示的是经过主干网后输出的特征图,特征图输入head中进行检测,包括类别和位置的检测。
1 | # YOLOv5 v6.0 head |
运行models文件夹下yolo.py文件,得到的解析图如下所示: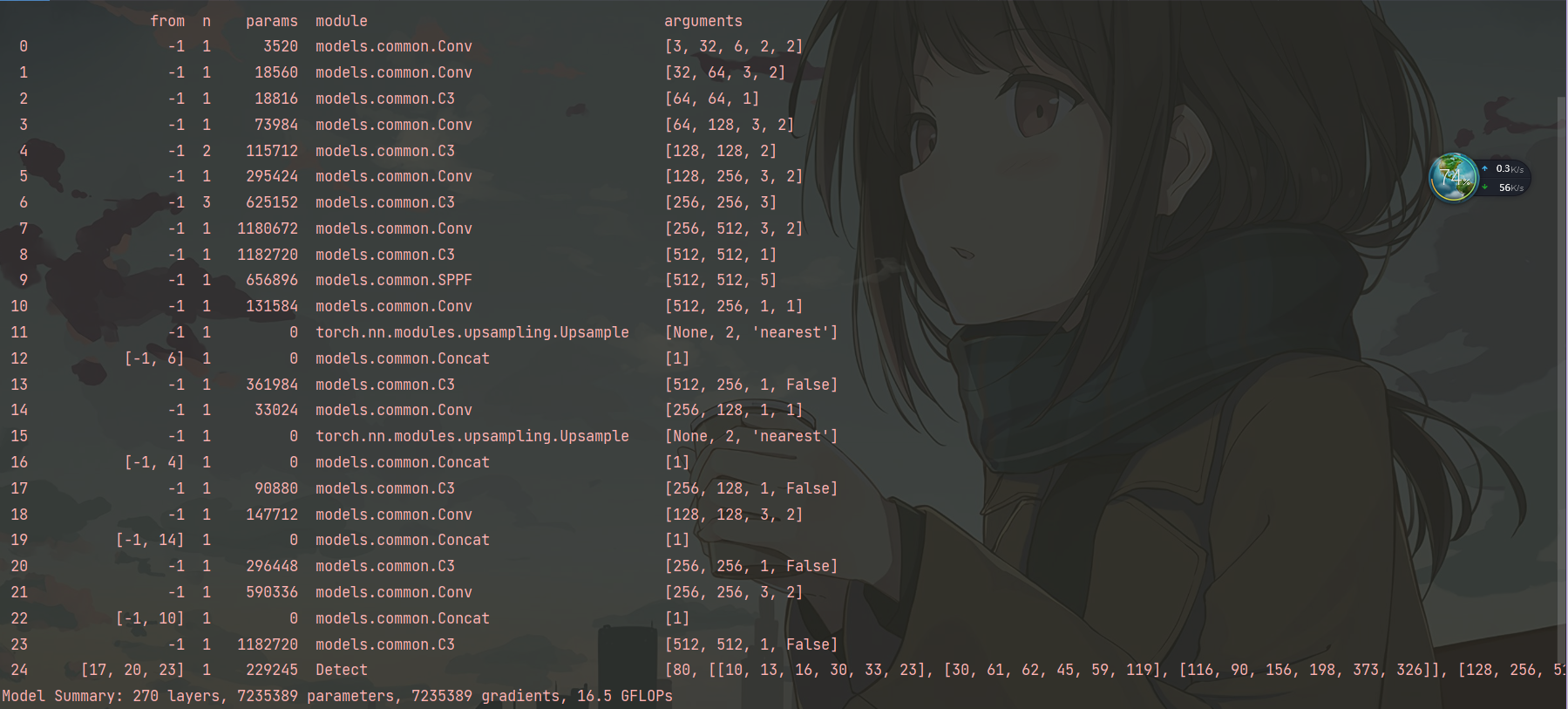
与上面的模型似乎不太一样。
后面弄清楚了再来补充。
common.py
该部分是backbone各个模块参数讲解。
utils文件夹——工具包
这三个文件夹都用的很少,需要用到时再做了解。
aws文件夹
里面是一些跟其他语言对接的文件
flask_rest_api
存放了做后端API的一些例程代码和封装好的函数
loggers
终端需要打印任务信息的接口函数。
工具包函数
| 文件名 | 备注 |
|---|---|
| activations.py | 激活函数 |
| augmentations.py | 图片增强函数 |
| autoanchor.py | 自动锚点工具函数 |
| autobatch.py | 自动批量处理工具 |
| benchmarks.py | / |
| callbacks.py | 回调函数 |
| datasets.py | 用于数据加载和数据集的工具 |
| downloads.py | 下载工具 |
| general.py | 通用工具函数 |
| loss.py | 计算损失函数工具 |
| metrics.py | 模型验证函数 |
| plots.py | 可视化工具 |
| torch_utils.py | PyTorch相关工具 |
主目录下其他.py代码
detect.py
对图像、视频、路径、流媒体等进行推理检测。
export.py
导出YOLOv5 PyTorch模型到其他格式。如ONNX、OpenVINO、Core ML以及TensorFlow相关的格式。
train.py
训练程序,在自定义数据集上训练YOLOv5模型。
val.py
在自定义数据集上验证经过训练的YOLOv5模型的准确性 。
.jpg)
.jpg)
.jpg)
.jpg)
.png)
.jpg)