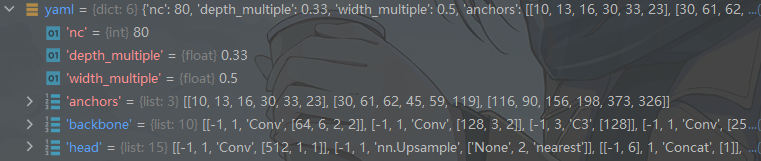
defparse_model(d, ch): # model_dict, input_channels(3) LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10}{'module':<40}{'arguments':<30}") anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'] na = (len(anchors[0]) // 2) ifisinstance(anchors, list) else anchors # number of anchors no = na * (nc + 5) # number of outputs = anchors * (classes + 5) # 这部分很简单,读出配置dict里面的参数,na是判断anchor的数量,no是根据anchor数量推断的输出维度,比如对于coco是255。输出维度=anchor数量*(类别数量+置信度+xywh四个回归坐标)。
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out for i, (f, n, m, args) inenumerate(d['backbone'] + d['head']): # from, number, module, args m = eval(m) ifisinstance(m, str) else m # eval strings for j, a inenumerate(args): try: args[j] = eval(a) ifisinstance(a, str) else a # eval strings except NameError: pass # 这里开始迭代循环backbone与head的配置。f,n,m,args分别代表着从哪层开始,模块的默认深度,模块的类型和模块的参数。
n = n_ = max(round(n * gd), 1) if n > 1else n # depth gain # 网络用n*gd控制模块的深度缩放,比如对于yolo5s来讲,gd为0.33,也就是把默认的深度缩放为原来的1/3。深度在这里指的是类似CSP这种模块的重复迭代次数。而宽度一般我们指的是特征图的channel。一般控制模型的缩放,我们就会控制深度、宽度和resolution(efficientnet的思路)。
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]: c1, c2 = ch[f], args[0] if c2 != no: # if not output c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]] if m in [BottleneckCSP, C3, C3TR, C3Ghost]: args.insert(2, n) # number of repeats n = 1 # 对于以上的这几种类型的模块,ch是一个用来保存之前所有的模块输出的channle,ch[-1]代表着上一个模块的输出通道。args[0]是默认的输出通道。 elif m is nn.BatchNorm2d: args = [ch[f]] elif m is Concat: c2 = sum(ch[x] for x in f) elif m is Detect: args.append([ch[x] for x in f]) ifisinstance(args[1], int): # number of anchors args[1] = [list(range(args[1] * 2))] * len(f) elif m is Contract: c2 = ch[f] * args[0] ** 2 elif m is Expand: c2 = ch[f] // args[0] ** 2 else: c2 = ch[f]
m_ = nn.Sequential(*(m(*args) for _ inrange(n))) if n > 1else m(*args) # module t = str(m)[8:-2].replace('__main__.', '') # module type np = sum(x.numel() for x in m_.parameters()) # number params m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f}{t:<40}{str(args):<30}') # print save.extend(x % i for x in ([f] ifisinstance(f, int) else f) if x != -1) # append to savelist layers.append(m_) if i == 0: ch = [] ch.append(c2) return nn.Sequential(*layers), sorted(save)
逐步分析这个函数:
1 2 3 4
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10}{'module':<40}{'arguments':<30}") anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'] na = (len(anchors[0]) // 2) ifisinstance(anchors, list) else anchors # number of anchors no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
for i, (f, n, m, args) inenumerate(d['backbone'] + d['head']): # from, number, module, args m = eval(m) ifisinstance(m, str) else m # eval strings for j, a inenumerate(args): try: args[j] = eval(a) ifisinstance(a, str) else a # eval strings except NameError: pass
elif m is nn.BatchNorm2d: args = [ch[f]] elif m is Concat: c2 = sum(ch[x] for x in f) elif m is Detect: args.append([ch[x] for x in f]) ifisinstance(args[1], int): # number of anchors args[1] = [list(range(args[1] * 2))] * len(f) elif m is Contract: c2 = ch[f] * args[0] ** 2 elif m is Expand: c2 = ch[f] // args[0] ** 2 else: c2 = ch[f]
t = str(m)[8:-2].replace('__main__.', '') # module type np = sum(x.numel() for x in m_.parameters()) # number params m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f}{t:<40}{str(args):<30}') # print
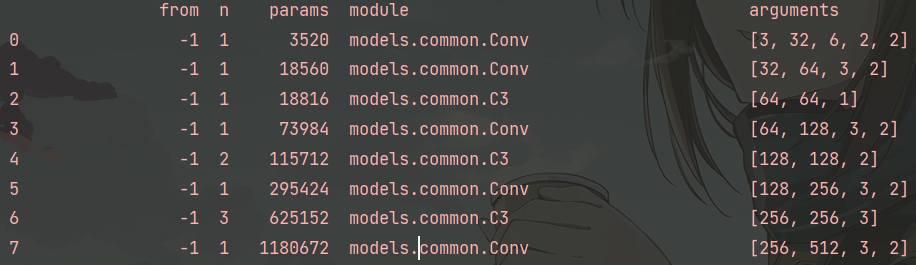
这里做了一些输出打印,可以看到每一层module构建的编号、参数量等情况,如下所示:
1 2 3 4 5 6
save.extend(x % i for x in ([f] ifisinstance(f, int) else f) if x != -1) # append to savelist layers.append(m_) if i == 0: ch = [] ch.append(c2) return nn.Sequential(*layers), sorted(save)
m = self.model[-1] # Detect() ifisinstance(m, Detect): s = 256# 2x min stride m.inplace = self.inplace m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward m.anchors /= m.stride.view(-1, 1, 1) check_anchor_order(m) self.stride = m.stride self._initialize_biases() # only run once
defforward(self, x): x = self.cv1(x) with warnings.catch_warnings(): warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
.jpg)
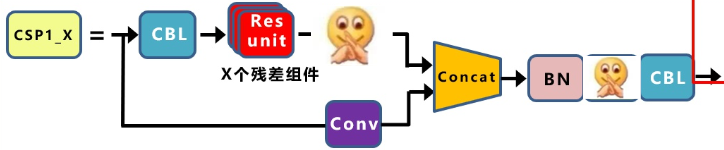
.jpg)
.jpg)
.jpg)
.jpg)
.png)
.jpg)