.jpg)
Paper Reading 1|YOLO-Z
文献阅读1-YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles
本文的中文题目为:YOLO-Z:基于改进YOLOv5的自动驾驶车辆小目标检测算法。
概述
本研究探索了如何对YOLOv5进行修改,以提高其在检测较小目标时的性能,并在自动赛车中进行了特殊应用。为了实现这一点,作者研究了替换模型的某些结构会如何影响性能和推理时间。在这一过程中在不同的尺度上提出一系列的模型YOLO-Z,并得到高达6.9%的改善,相比原YOLOv5推理时间检测更小的目标时的成本就增加3ms。
数据集(Dataset)
本文所采用的数据集为基于自动驾驶赛车视角的带注释的锥体数据集。该数据集包括数字增强图像和具有挑战性天气条件的情况。数据集共有4类圆锥体(黄色、蓝色、橙色和大橙色),接近4000张图像。
数据集以65:15:20的比例分为训练、验证和测试。
架构改进
YOLOv5使用yaml文件来指导解析器如何构建模型。为了实现新的YOLOv5模型结构,作者为原有的YOLOv5的每个构建模块或层提供参数,并在必要时指导解析器如何构建它。换句话说,作者利用YOLOv5提供的基础和实验网络块,同时在需要模拟所需结构的地方实现额外的块。
Backbone部分
模型的Backbone是用于获取输入图像并从中提取特征映射的组件。这是任何目标检测器的关键步骤,因为它是负责从输入图像提取上下文信息以及将该信息提取为模式的主要结构。
作者尝试用2个Backbone替换YOLOv5中现有的Backbone。
- ResNet是一种流行的结构,它引入残差连接来减少在深层神经网络中收益递减的影响。
- DenseNet使用类似的连接,在网络中尽可能多地保存信息。实现这些结构需要将它们分解为基本块,并确保各层适当的通信。这包括确保正确的特征图尺寸,这有时需要为模型的宽度和深度略微修改缩放因子。
改进部分如下
- 使用ResNet50
- 按比例缩小DenseNet
- YOLOv5利用了Backbone和Neck之间的空间金字塔池化(SPP)层,改进的代码中没有用到。
实验结果:对于小目标 DenseNet性能更好,增加的推理时间也相对较少,ResNet性能较差。
Neck部分
Neck部分的作用是将Backbone提取的信息反馈到Head之前尽可能多地聚合这些信息。该结构通过防止小目标信息丢失,在传递小目标信息方面发挥了重要作用。它通过再次提高特征图的分辨率来做到这一点,这样来自Backbone的不同层的特征就可以被聚合,以提升整体的检测性能。
改进部分:
当前的PAN-Net替换为bi-FPN。
虽然都保留了类似的特征,但复杂性不同,因此实现所需的层数和连接数也不同。
其他修改
作者提到为了提高小目标检测性能,YOLOv5的改进除了输入图像的大小之外,还可以修改模型的深度和宽度(废话),以改变处理的主要方向;Neck和Head的层连接方式也可以手动改变,以便专注于检测特定的特征图。
作者探索了涉及高分辨率特征映射的重定向连接的效果,以便将它们直接反馈到Neck和Head,做了如下修改:
- 扩大Neck以适应额外的特征图来实现
- 通过替换最低分辨率的特征图以适应新的特征图来实现
用这两种方式在Neck中整合。
实验结果

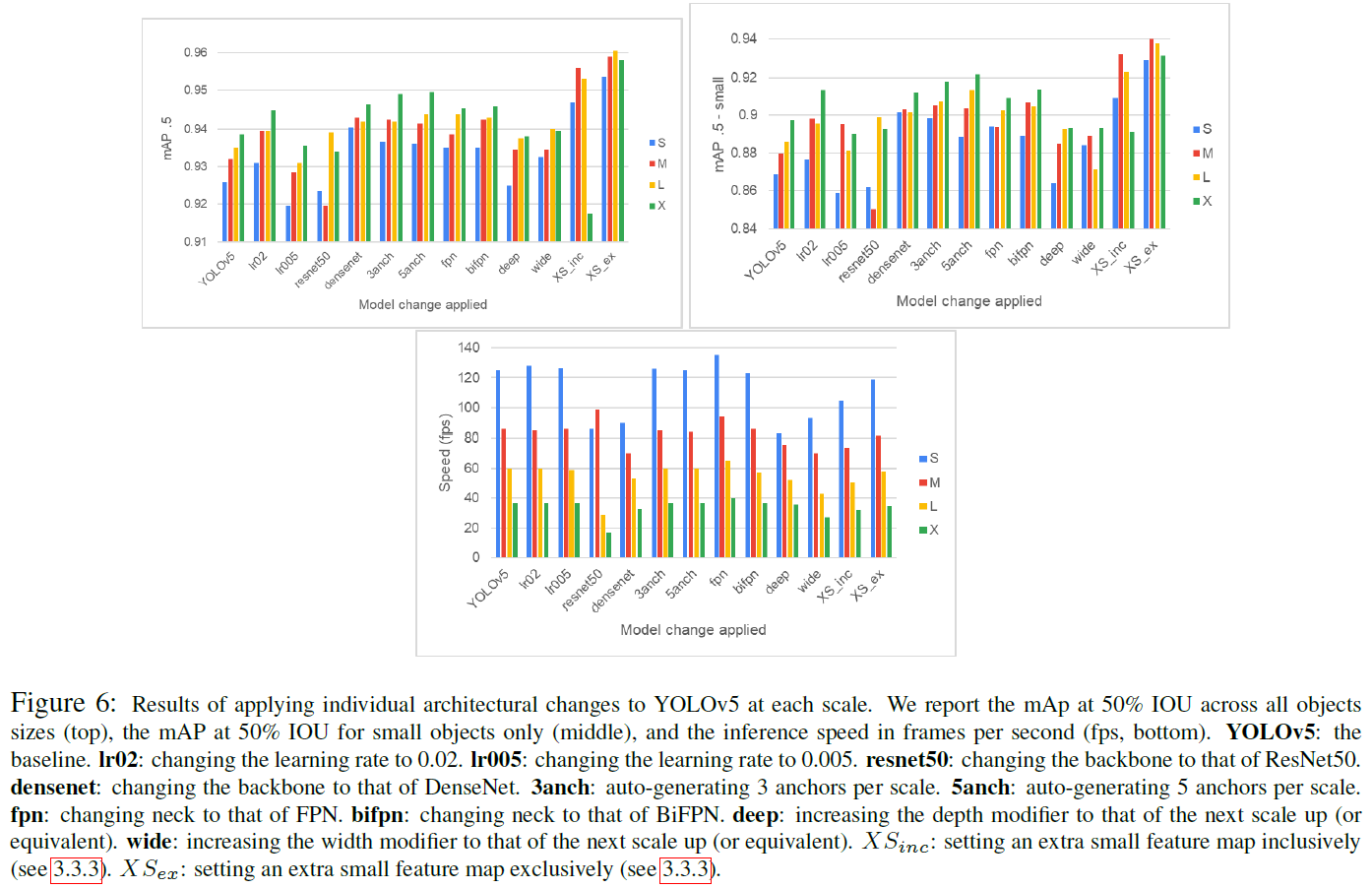
Backbone改进的影响
DenseNet在推理时间(约3ms)相对较低的固定增加时,始终显示出显著的改进。作者的结论是:一般来说,DenseNet是一个更适合于小尺度目标检测。在较小比例的模型中,这可能是因为没有足够深的网络来获得ResNet骨干网的好处,而DenseNet在保存特征地图的细节方面做得很好。
Neck结构改进的影响
使用FPN只在S尺度上优于双FPN。
Feature maps
作者的实验表明重定向向颈部和头部提供的特征映射具有最显著的影响。在头部包含了更高分辨率的地图后,小对象最终占据了更多的像素,因此具有更大的影响力,而不是在脊柱的卷积阶段“丢失”。
但对于超大规模的(即yolov5x),在这种情况下,改进并不显著,保持较低分辨率的特征图实际上似乎对性能有害。
Influence of the number of anchors(锚点数)
作者的实验表明:让YOLO根据所提供的数据集生成锚被证明在性能上是有效的,而且不会影响推理时间。在S模型下,3个锚点的表现优于5个锚点的表现,而在M模型下,差距减小。另一方面,L模型和X模型在5个锚点显示出更好的性能。
结论:更复杂或更深入的模型可能确实受益于额外的锚点,或者换句话说,可能更有能力利用额外锚点提供的细节。
其他因素
- 更大的学习率被证明可以更好地利用模型
- 较宽的模型(较高的宽度乘法器)对较小的尺度显示出积极的影响,而对较深的尺度(图6中既深又宽)则相反。
- 类型的改变对推理速度有明显的负面影响,阻碍了它们的使用。
改进模型
作者通过使用上述修改方法的各种组合进行了其他测试,以寻找进一步偏离原始但同时又能进一步提高性能的模型——即YOLO-z,结论如下:
- Neck的FPN结构往往优于双FPN
- X量表,它似乎从这些变化中获益较少,即使使用不同的颈部结构,也不会像其他量表那样带来显著的改善。
- 对于所有对象,在50% IoU的绝对mAP上,YOLO-Z模型的性能平均提高了2.7,而对于所有尺度上相同IoU的小对象,性能的绝对提高了5.9。这是以平均增加2.6ms的推理时间为代价的。
讨论与结论
在对YOLOv5进行调整以更好地检测更小的目标的方法的实验中,本文能够识别体系结构修改,这种修改在性能上比原始的检测器有明显改善,而且成本相对较低,因为新的模型保持了实时推理速度。
所应用的技术,即自动赛车技术,可以从这样的改进中获益良多。在这项工作中,不仅显著提高了Baseline模型的性能,而且还确定了一些特定的技术,这些技术可以应用于任何其他应用程序,包括检测小或远的物体。
最终结果是YOLO-Z系列的模型优于的YOLOv5类,同时保留一个推理时间等实时应用程序兼容的自动化赛车(见表2和图7)。特别是较小的目标是本研究的重点(图7中,中间),而对于中等大小的目标(下图),性能是稳定的。
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.png)