.jpg)
Yolov5学习笔记9|YOLOv5-Face|改进原理解读与论文复现
Yolov5改进|YOLOv5-Face|改进原理解读与论文复现
YOLOv5Face的设计目标和主要贡献
设计目标
YOLOv5Face针对人脸检测的对YOLOv5进行了再设计和修改,考虑到大人脸、小人脸、Landmark监督等不同的复杂性和应用。YOLOv5Face的目标是为不同的应用程序提供一个模型组合,从非常复杂的应用程序到非常简单的应用程序,以在嵌入式或移动设备上获得性能和速度的最佳权衡。
主要贡献
- 重新设计了YOLOV5来作为一个人脸检测器,并称之为YOLOv5Face。对网络进行了关键的修改,以提高平均平均精度(mAP)和速度方面的性能;
- 设计了一系列不同规模的模型,从大型模型到中型模型,再到超小模型,以满足不同应用中的需要。除了在YOLOv5中使用的Backbone外,还实现了一个基于ShuffleNetV2的Backbone,它为移动设备提供了最先进的性能和快速的速度;
- 在WiderFace数据集上评估了YOLOv5Face模型。在VGA分辨率的图像上,几乎所有的模型都达到了SOTA性能和速度。这也证明了前面的结论,不需要重新设计一个人脸检测器,因为YOLO5就可以完成它。
YOLOv5-Face的结构
YOLOv5-Face模型架构
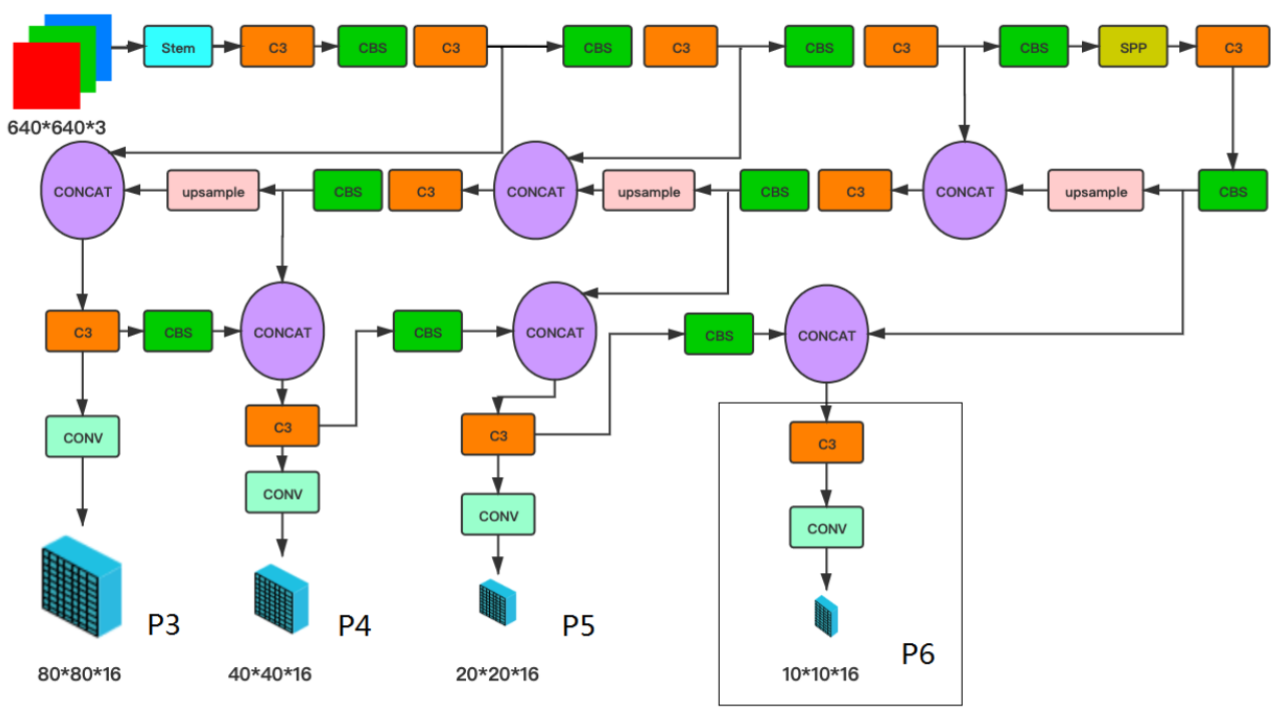
YOLOv5Face是以YOLOv5作为Baseline来进行改进和再设计以适应人脸检测。这里主要是检测小脸和大脸的修改。
YOLO5人脸检测器的网络架构如图1所示。它由Backbone、Neck和Head组成,描述了整体的网络体系结构。在YOLOv5中,使用了CSPNet Backbone。在Neck中使用了SPP和PAN来融合这些特征。在Head中也都使用了回归和分类。
CBS Block
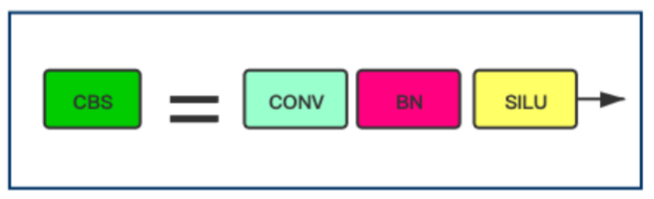
在上图中重新定义了一个CBS Block,它由Conv、BN和SiLU激活函数组成。但其实架构和Yolov5的一样。
对应的代码如下:
1 | class Conv(nn.Module): |

在上图中显示了Head的输出标签,其中包括边界框(bbox)、置信度(conf)、分类(cls)和5-Point Landmarks。这些Landmarks是对YOLOv5的改进点,使其成为一个具有Landmarks输出的人脸检测器。如果没有Landmarks,最后一个向量的长度应该是6而不是16。
请注意,P3中的输出尺寸80×80×16,P4中的40×40×16,P5中的20×20×16,可选P6中的10×10×16为每个Anchor。实际的尺寸应该乘以Anchor的数量。
Stem Block
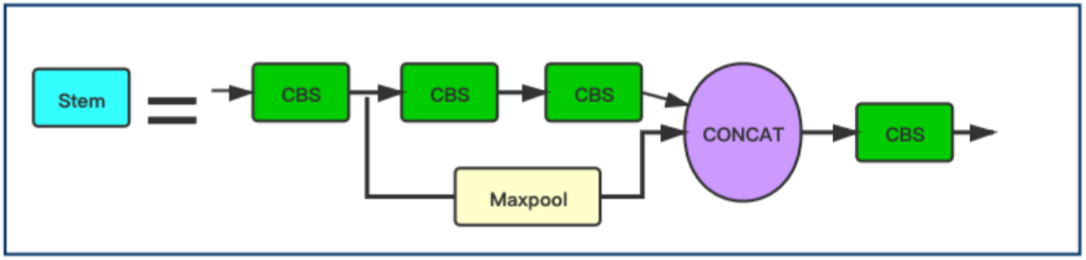
上图为stem,它同于取代Yolov5中原来的Focus层(实际上在yolov5-v5.0之后就没有Focus层了)。在Yolov5中引入Stem模块用于人脸检测时Yolov5-Face创新之一。
1 | class StemBlock(nn.Module): |
用Stem模块替代网络中原有的Focus模块,提高了网络的泛化能力,降低了计算复杂度,同时性能也没有下降。
1 | # YOLOv5 backbone |
Stem模块的图示中虽然都是用的CBS,但是看代码可以看出来第2个和第4个CBS是1×1卷积,第1个和第3个CBS是3×3,stride=2的卷积。配合yaml文件可以看到stem以后图像大小由640×640变成了160×160。

在上图中,显示了一个CSP Block(C3)。CSP Block的设计灵感来自于DenseNet。但是,不是在一些CNN层之后添加完整的输入和输出,输入被分成 2 部分。其中一半通过一个CBS Block,即一些Bottleneck Blocks,另一半是经过Conv层进行计算:
1 | class C3(nn.Module): |
Bottleneck Block
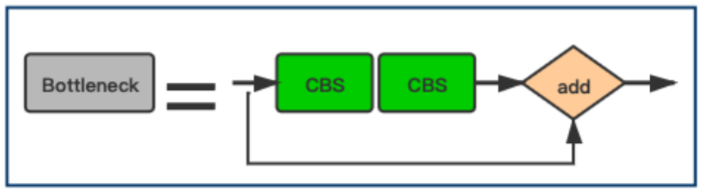
上图即为C3模块中的Bottleneck层。
1 | class Bottleneck(nn.Module): |
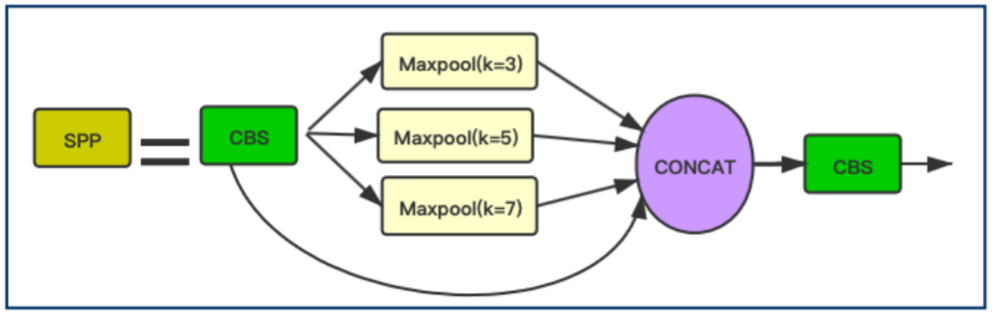
上图为SPP Block、。YOLOv5Face在这个Block中把YOLOv5中的13×13,9×9,5×5的kernel size被修改为7×7,5×5,3×3,这个改进更适用于人脸检测并提高了人脸检测的精度。
1 | class SPP(nn.Module): |
同时,YOLOv5Face添加一个stride=64的P6输出块,P6可以提高对大人脸的检测性能。(之前的人脸检测模型大多关注提高小人脸的检测性能,这里作者关注了大人脸的检测效果,提高大人脸的检测性能来提升模型整体的检测性能)。P6的特征图大小为10x10。
同时,YOLOv5Face添加一个stride=64的P6输出块,P6可以提高对大人脸的检测性能。(之前的人脸检测模型大多关注提高小人脸的检测性能,这里作者关注了大人脸的检测效果,提高大人脸的检测性能来提升模型整体的检测性能)。P6的特征图大小为10x10。
输入改进
YOLOv5Face作者发现一些目标检测的数据增广方法并不适合用在人脸检测中,包括上下翻转和Mosaic数据增广。删除上下翻转可以提高模型性能。对小人脸进行Mosaic数据增广反而会降低模型性能,但是对中尺度和大尺度人脸进行Mosaic可以提高性能。随机裁剪有助于提高性能。
这里主要还是COCO数据集和WiderFace数据集尺度有差异,WiderFace数据集小尺度数据相对较多。
Landmark回归
Landmark是人脸的重要特征。它们可以用于人脸比对、人脸识别、面部表情分析、年龄分析等任务。传统Landmark由68个点组成。它们被简化为5点时,这5点Landmark就被广泛应用于面部识别。人脸标识的质量直接影响人脸对齐和人脸识别的质量。
一般的物体检测器不包括Landmark。可以直接将其添加为回归Head。因此,作者将它添加到YOLO5Face中。Landmark输出将用于对齐人脸图像,然后将其发送到人脸识别网络。
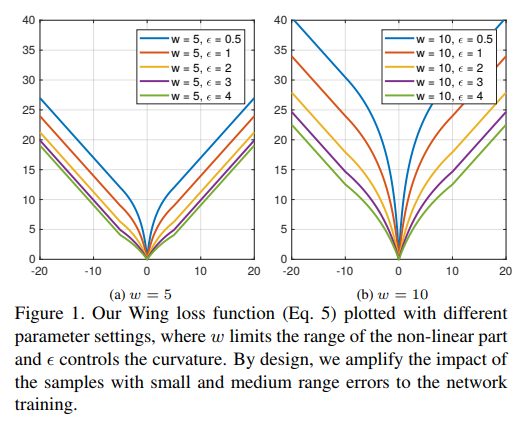
用于Landmark回归的一般损失函数为L2、L1或smooth-L1。MTCNN使用的就是L2损失函数。然而,作者发现这些损失函数对小的误差并不敏感。为了克服这个问题,提出了Wing loss:
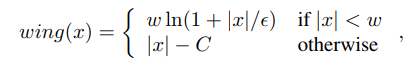
w: 正数w将非线性部分的范围限制在[-w,w]之间;
$\varepsilon $: 约束非线性区域的曲率,并且$C=\omega-\omega ln(1+\frac{x}{\varepsilon)}$是一个常数,可以平滑的连接分段的线性和非线性部分。$\varepsilon$的取值是一个很小的数值,因为它会使网络训练变得不稳定,并且会因为很小的误差导致梯度爆炸问题。
实际上,的Wing loss函数的非线性部分只是简单地采用ln(x)在[$\frac{\varepsilon}{\omega},1+\frac{\varepsilon}{\omega}$]之间的曲线,并沿X轴和Y轴将其缩放比例为w。另外,沿y轴应用平移以使wing(0)=0,并在损失函数上施加连续性。
landmark的获取:
1 | #landmarks |
Wing Loss的计算如下:
1 | class WingLoss(nn.Module): |
分析比较L1,L2和Smooth L1损失函数
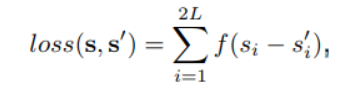
其中s是人脸关键点的ground-truth,函数f(x)就等价于:
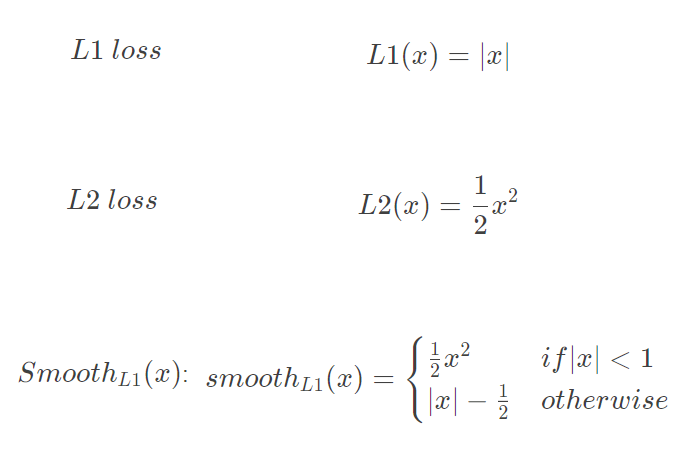
损失函数对x的导数分别为:
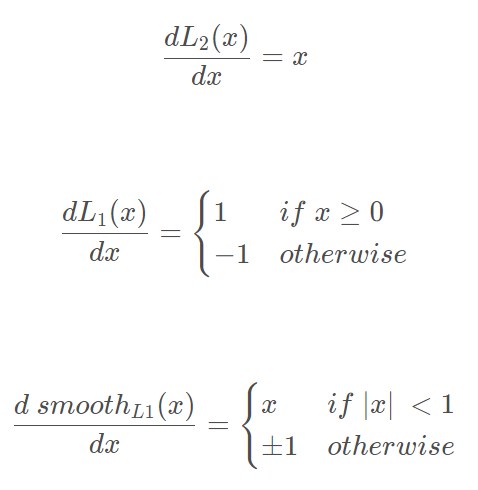
L2损失函数,当x增大时L2 loss对x的导数也增大,这就导致训练初期,预测值与ground-truth差异过大时,损失函数对预测值的梯度十分大,导致训练不稳定。
L1 loss的导数为常数,在训练后期,预测值与ground-truth差异很小时, 损失对预测值的导数的绝对值仍然为1,此时学习率(learning rate)如果不变,损失函数将在稳定值附近波动,难以继续收敛达到更高精度。
smooth L1损失函数,在x较小时,对x的梯度也会变小,而在x很大时,对x的梯度的绝对值达到上限 1,也不会太大以至于破坏网络参数。smooth L1完美地避开了L1和L2损失的缺陷。
此外,根据fast rcnn的说法,”… L1 loss that is less sensitive to outliers than the L2 loss used in R-CNN and SPPnet.” 也就是smooth L1让loss对于离群点更加鲁棒,即相比于L2损失函数,其对离群点、异常值(outlier)不敏感,梯度变化相对更小,训练时不容易跑飞。
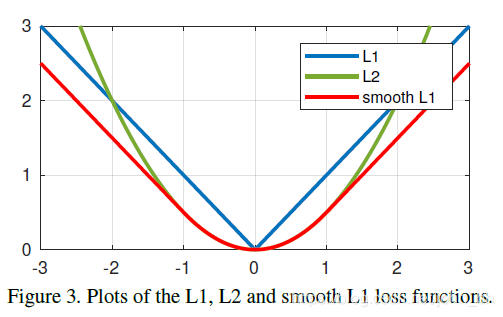
上图描绘了这些损失函数的曲线图。需要注意的是,Smoolth L1损失是Huber损失的一种特殊情况,L2损失函数在人脸关键点检测中被广泛应用,然而,L2损失对异常值很敏感。
为什么是Wing Loss?
上一部分中分析的所有损失函数在出现较大误差时表现良好。这说明神经网络的训练应更多地关注具有小或中误差的样本。为了实现此目标,提出了一种新的损失函数,即基于CNN的面部Landmark定位的Wing Loss。
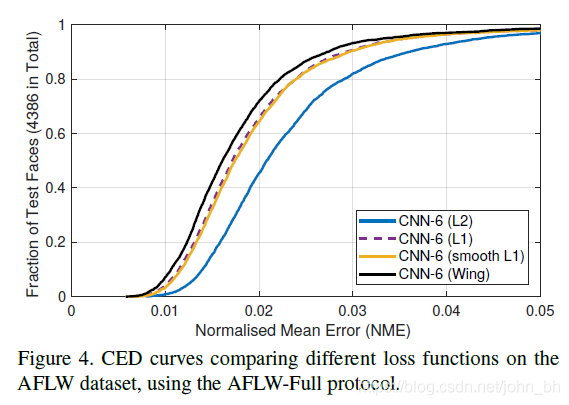
当NME在0.04的时候,测试数据比例已经接近1了,所以在0.04到0.05这一段,也就是所谓的large errros段,并没有分布更多的数据,说明各损失函数在large errors段都表现很好。
模型表现不一致的地方就在于small errors和medium errors段,例如,在NME为0.02的地方画一根竖线,相差甚远的。因此作者提出训练过程中应该更多关注samll or medium range errros样本。
可以使用ln x来增强小误差的影响,它的梯度是$\frac{1}{x}$,对于接近0的值就会越大,optimal step size为$x^2$,这样gradient就由small errors“主导”,step size由large errors“主导”。这样可以恢复不同大小误差之间的平衡。
但是,为了防止在可能的错误方向上进行较大的更新步骤,重要的是不要过度补偿较小的定位错误的影响。这可以通过选择具有正偏移量的对数函数来实现。
但是这种类型的损失函数适用于处理相对较小的定位误差。在wild人脸关键点检测中,可能会处理极端姿势,这些姿势最初的定位误差可能非常大,在这种情况下,损失函数应促进从这些大错误中快速恢复。这表明损失函数的行为应更像L1或L2。由于L2对异常值敏感,因此选择了L1。
所以,对于小误差,它应该表现为具有偏移量的对数函数,而对于大误差,则应表现为L1。因此复合损失函数Wing Loss就诞生了。
Yolov5-Face的后处理NMS
其实本质上没有改变,这里仅仅给出对比的代码。
Yolov5的NMS代码如下:
1 | def non_max_suppression(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, labels=()): |
Yolov5-Face的NMS代码如下:
1 | def non_max_suppression_face(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, labels=()): |
论文复现
下载后,解压缩位置放到yolov5-face-master项目里data文件夹下的widerface文件夹下。
- 运行train2yolo.py和val2yolo.py
把数据集转成yolo的训练格式,
- 运行train.py
OpenCV-C++部署
参数配置
该部分主要是输入输出尺寸、Anchor以及Strides设置等。
代码如下:
1 | const float anchors[3][6] = { {4,5, 8,10, 13,16}, |
模型加载以及Sigmoid的定义
该部分主要设置ONNX模型的加载。
1 | YOLO::YOLO(Net_config config) |
后处理部分
这里对坐标的处理和Yolov5保持一致,但是由于多出来的Landmark,所以也多出了这一部分的处理:
1 | if (box_score > this->objThreshold) |
参考文献
[1].https://github.com/hpc203/yolov5-face-landmarks-opencv-v2
[2].https://github.com/deepcam-cn/yolov5-face
[3].YOLO5Face: Why Reinventing a Face Detector
[4].https://zhuanlan.zhihu.com/p/375966269
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.png)